Web Scraping avec python
Pour sourcer des données pour des projets de science des données, vous comptez souvent sur
des bases de données SQL et NoSQL , des API ou des ensembles de données CSV prêts à l'emploi.
Le problème est que vous ne pouvez pas toujours trouver un ensemble de données sur votre sujet,
les bases de données ne sont pas tenues à jour et les API sont chères ou ont des limites d'utilisation.
Si les données que vous recherchez se trouvent sur une page Web, la solution à tous ces problèmes
est le grattage Web .
Dans ce tutoriel, nous allons apprendre à gratter plusieurs pages Web avec Python en utilisant
BeautifulSoup et les requêtes . Nous effectuerons ensuite une analyse simple en utilisant pandas et
Vous devriez déjà avoir une compréhension de base du HTML, une bonne compréhension des bases
de Python et une idée approximative de ce qu'est le grattage Web. Si vous n'êtes pas à l'aise avec
ceux-ci, je vous recommande ce didacticiel de grattage Web pour débutants .
Grattage des données de plus de 2000 films
Nous voulons analyser les distributions des notes de films IMDB et Metacritic pour voir si nous
trouvons quelque chose d'intéressant. Pour ce faire, nous allons d'abord récupérer les données de
plus de 2000 films.
Il est essentiel d'identifier l'objectif de notre grattage dès le début. L'écriture d'un script de scraping
peut prendre beaucoup de temps, surtout si nous voulons scraper plus d'une page Web. Nous voulons
éviter de passer des heures à écrire un script qui récupère des données dont nous n'aurons pas
réellement besoin.
Déterminer les pages à gratter
Une fois que nous avons établi notre objectif, nous devons ensuite identifier un ensemble efficace de pages à gratter.
Nous voulons trouver une combinaison de pages qui nécessite un nombre relativement faible de requêtes. Une demande est ce qui se passe chaque fois que nous accédons à une page Web. Nous 'demandons' le contenu d'une page au serveur. Plus nous faisons de requêtes, plus notre script aura besoin de s'exécuter longtemps et plus la pression sur le serveur sera grande.
Une façon d'obtenir toutes les données dont nous avons besoin est de compiler une liste de noms de films et de l'utiliser pour accéder à la page Web de chaque film sur les sites Web IMDB et Metacritic.
Puisque nous voulons obtenir plus de 2000 évaluations à la fois d'IMDB et de Metacritic, nous
devrons faire au moins 4000 demandes. Si nous faisons une requête par seconde, notre script aura
besoin d'un peu plus d'une heure pour faire 4000 requêtes. Pour cette raison, il vaut la peine
d'essayer d'identifier des moyens plus efficaces d'obtenir nos données.
Si nous explorons le site Web IMDB, nous pouvons découvrir un moyen de réduire de moitié le
nombre de demandes. Les scores métacritiques sont affichés sur la page du film IMDB, nous
pouvons donc gratter les deux notes avec une seule demande :
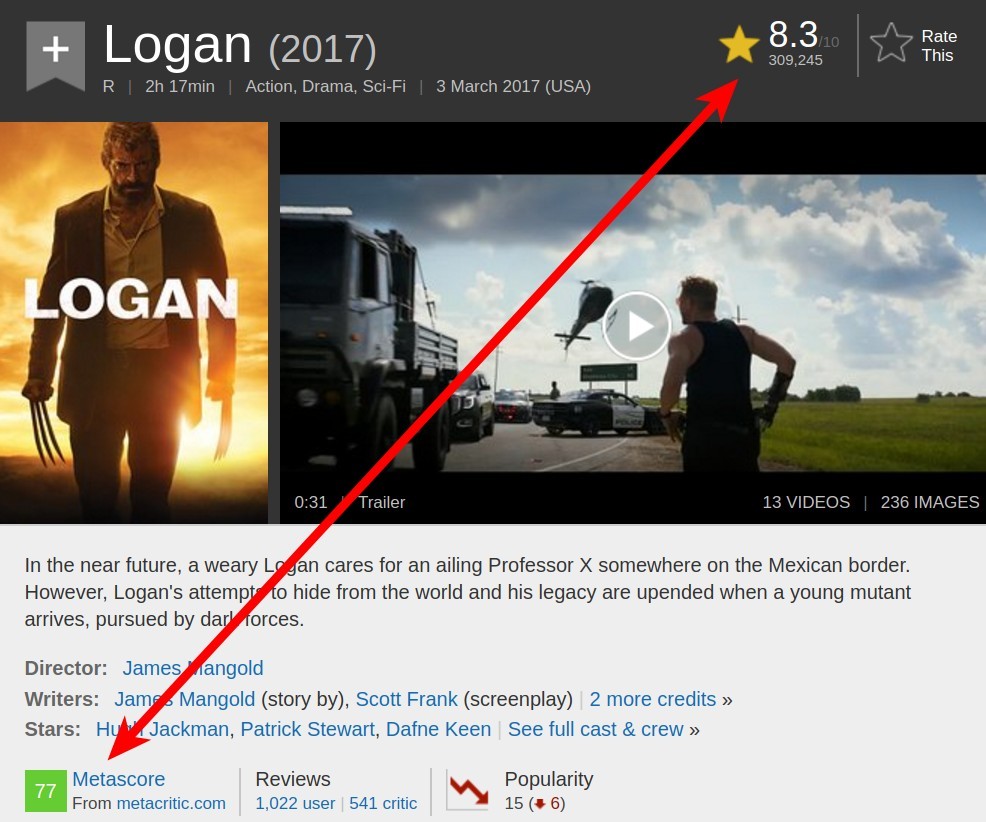
Si nous enquêtons davantage sur le site IMDB, nous pouvons découvrir la page ci-dessous.
Il contient toutes les données dont nous avons besoin pour 50 films. Compte tenu de notre objectif,
cela signifie que nous n'aurons à faire qu'une quarantaine de requêtes, soit 100 fois moins que notre
première option. Explorons plus avant cette dernière option.

Identification de la structure de l'URL
Notre défi est maintenant de nous assurer que nous comprenons la logique de l'URL au fur et
à mesure que les pages que nous voulons gratter changent. Si nous ne comprenons pas assez cette
logique pour pouvoir l'implémenter dans le code, alors nous arriverons à une impasse.
Si vous allez sur la page de recherche avancée d'IMDB , vous pouvez parcourir les films par année :
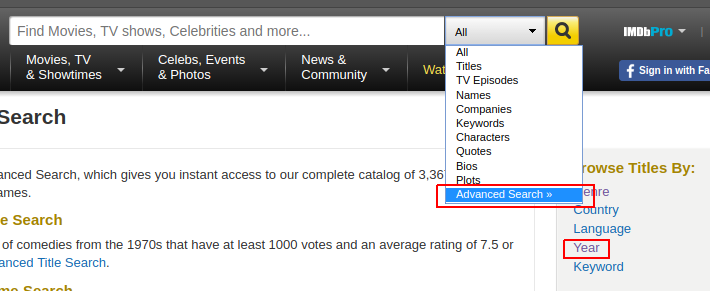
Parcourons par année 2017, trions les films de la première page par nombre de votes, puis passons à la page suivante. Nous arriverons à cette page Web , qui a cette URL :
![]()
Dans l'image ci-dessus, vous pouvez voir que l'URL a plusieurs paramètres après le point
d'interrogation :
release_date— Affiche uniquement les films sortis au cours d'une année spécifique.sort— Trie les films sur la page.sort=num_votes,descse traduit par un tri par nombre de votes dans un ordre décroissant .page— Spécifie le numéro de page.ref_— Nous amène à la page suivante ou précédente. La référence est la page sur laquelle nous sommes actuellement.adv_nxtetadv_prvsont deux valeurs possibles. Ils se traduisent pour passer à la page suivante et passer à la page précédente , respectivement.
Si vous parcourez ces pages et observez l'URL, vous remarquerez que seules les valeurs des
paramètres changent. Cela signifie que nous pouvons écrire un script pour correspondre à la
logique des modifications et faire beaucoup moins de demandes pour récupérer nos données.
Commençons à écrire le script en demandant le contenu de cette page Web unique : https://www.imdb.com/search/title?release_date=2017&sort=num_votes,desc&page=1. Dans la cellule de code suivante, nous allons :
- Importez la
get()fonction depuis lerequestsmodule. - Attribuez l'adresse de la page Web à une variable nommée
url. - Demandez au serveur le contenu de la page Web en utilisant
get(), et stockez la réponse du serveur dans la variableresponse. - Imprimer une petite partie du
responsecontenu de en accédant à son.textattribut (responseest maintenant unResponseobjet).
from requests import get
url = 'https://www.imdb.com/search/title?release_date=2017&sort=num_votes,desc&page=1'
response = get(url)
print(response.text[:500])<!DOCTYPE html><
htmlxmlns:og="https://ogp.me/ns#"xmlns:fb="https://www.facebook.com/2008/fbml">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="apple-itunes-app" content="app-id=342792525, app-argument=imdb:///?src=mdot">
<script type="text/javascript">
var ue_t0=window.ue_t0||+new Date();</script>
<script type="text/javascript">
var ue_mid = "A1EVAM02EL8SFB";Comprendre la structure HTML d'une seule page
Comme vous pouvez le voir sur la première ligne de response.text, le serveur nous a envoyé un document HTML. Ce document décrit la structure globale de cette page Web, ainsi que son contenu spécifique (ce qui rend cette page particulière unique).
Toutes les pages que nous voulons gratter ont la même structure globale. Cela implique qu'ils ont également la même structure HTML globale. Ainsi, pour écrire notre script, il suffira de comprendre la structure HTML d'une seule page. Pour ce faire, nous utiliserons les outils de développement du navigateur .
Si vous utilisez Chrome , cliquez avec le bouton droit sur un élément de page Web qui vous intéresse, puis cliquez sur Inspecter . Cela vous mènera directement à la ligne HTML qui correspond à cet élément :
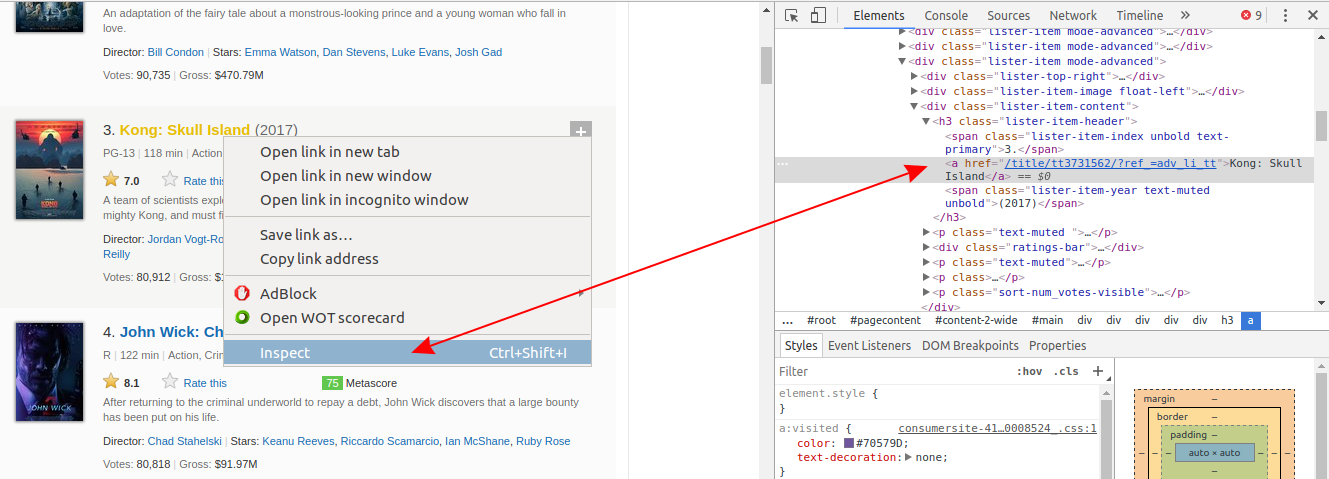
Cliquez avec le bouton droit sur le nom du film, puis cliquez avec le bouton gauche sur Inspecter . La ligne HTML surlignée en gris correspond à ce que l'utilisateur voit sur la page Web comme le nom du film.
Vous pouvez également le faire en utilisant à la fois Firefox et Safari DevTools.
Notez que toutes les informations de chaque film, y compris l'affiche, sont contenues dans une divbalise.
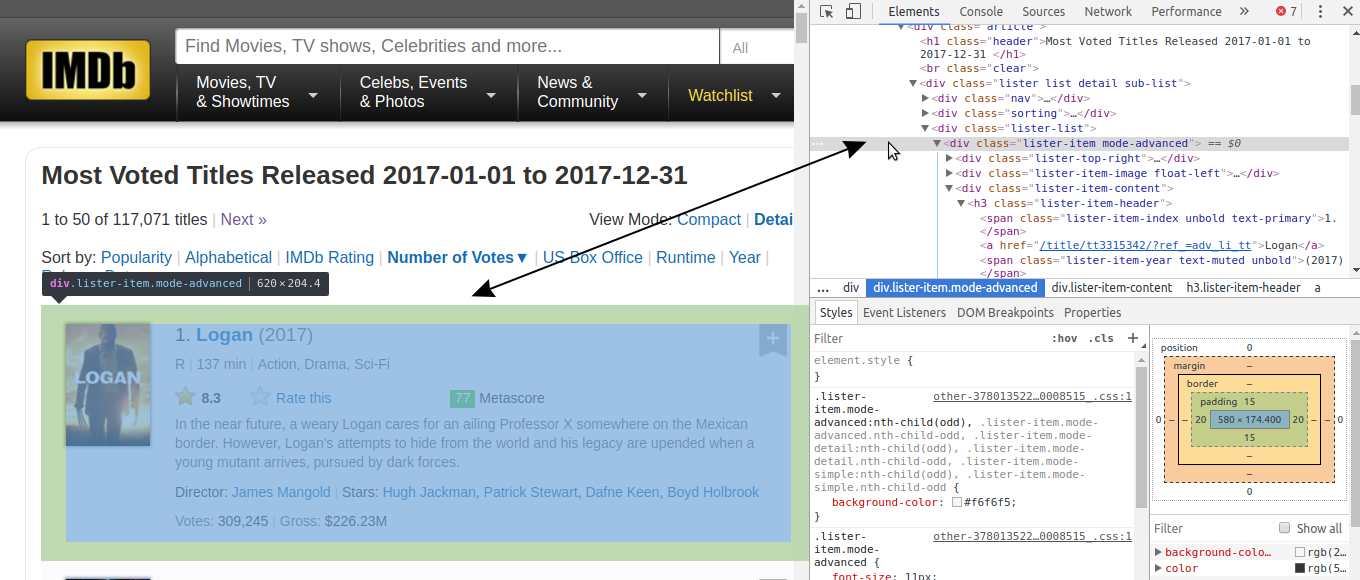
Il y a beaucoup de lignes HTML imbriquées dans chaque divbalise. Vous pouvez les explorer en cliquant sur ces petites flèches grises à gauche des lignes HTML correspondant à chacune div. Dans ces balises imbriquées, nous trouverons les informations dont nous avons besoin, comme la note d'un film.
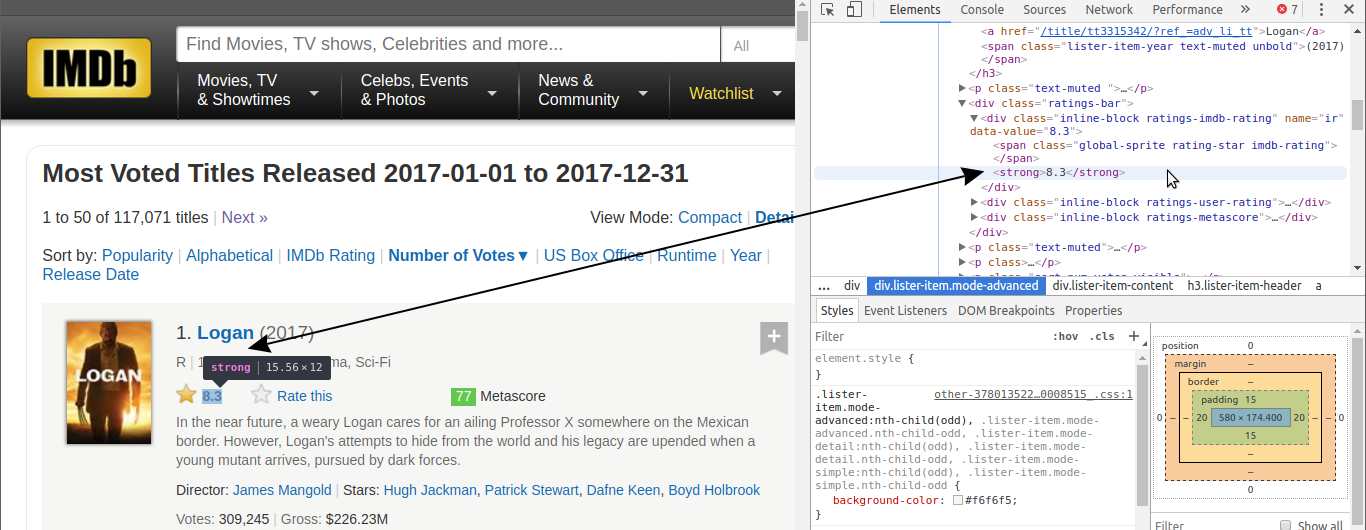
Il y a 50 films affichés par page, il devrait donc y avoir un divconteneur pour chacun. Extrayons tous ces 50 conteneurs en analysant le document HTML de notre requête précédente.
Utiliser BeautifulSoup pour analyser le contenu HTML
Pour analyser notre document HTML et extraire les 50 divconteneurs, nous utiliserons un module Python appelé BeautifulSoup , le module de grattage Web le plus courant pour Python.
Dans la cellule de code suivante, nous allons :
- Importez le
BeautifulSoupcréateur de classe à partir du packagebs4. - Analysez
response.texten créant unBeautifulSoupobjet et affectez cet objet àhtml_soup. L''html.parser'argument indique que nous voulons effectuer l'analyse à l'aide de l'analyseur HTML intégré de Python .
from bs4 import BeautifulSoup
html_soup = BeautifulSoup(response.text, 'html.parser')
type(html_soup)bs4.BeautifulSoupAvant d'extraire les 50 divconteneurs, nous devons déterminer ce qui les distingue des autres divéléments de cette page. Souvent, le signe distinctif réside dans l' class attribut . Si vous inspectez les lignes HTML des conteneurs d'intérêt, vous remarquerez que l' classattribut a deux valeurs : lister-itemet mode-advanced. Cette combinaison est unique à ces divconteneurs. Nous pouvons voir que c'est vrai en faisant une recherche rapide ( Ctrl + F). Nous avons 50 conteneurs de ce type, nous nous attendons donc à ne voir que 50 correspondances :
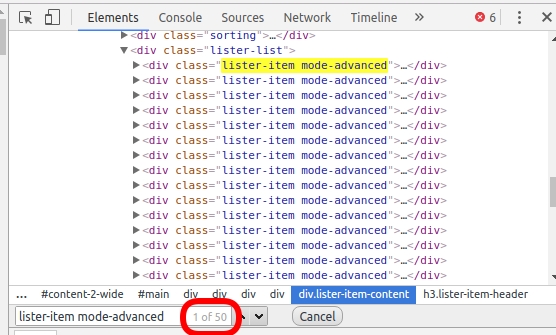
Utilisons maintenant la find_all() méthode pour extraire tous les divconteneurs qui ont un classattribut de lister-item mode-advanced:
movie_containers = html_soup.find_all('div', class_ = 'lister-item mode-advanced')
print(type(movie_containers))
print(len(movie_containers))<class 'bs4.element.ResultSet'>
50find_all()a renvoyé un ResultSetobjet qui est une liste contenant tous les 50 qui divsnous intéressent.
Maintenant, nous allons sélectionner uniquement le premier conteneur et extraire, tour à tour, chaque élément d'intérêt :
- Le nom du film.
- L'année de la sortie.
- La cote IMDB.
- Le métascore.
- Le nombre de voix.
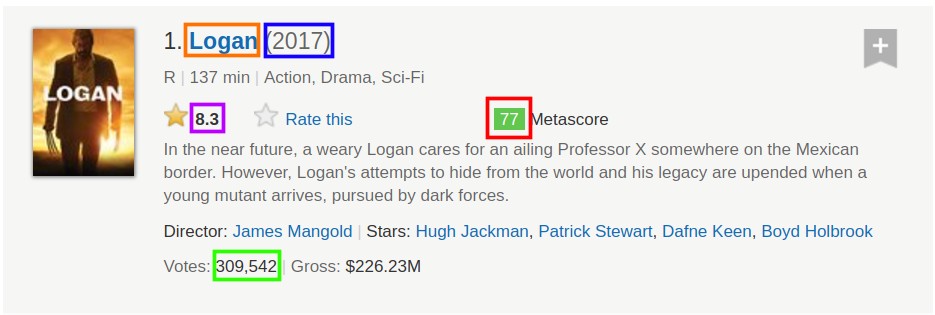
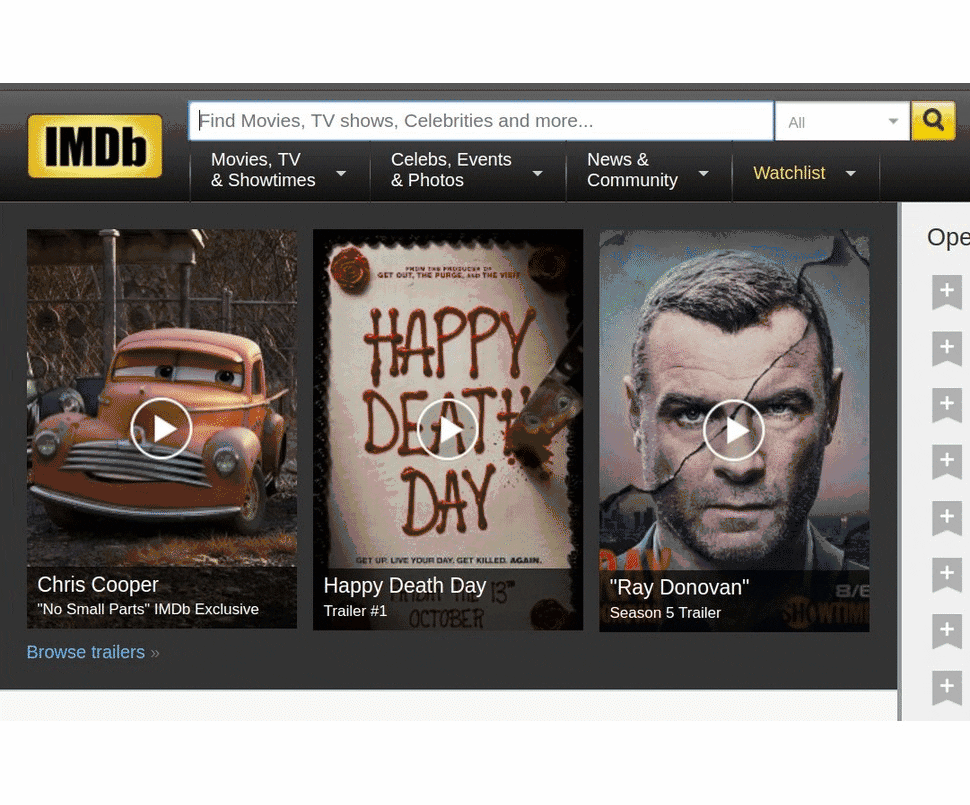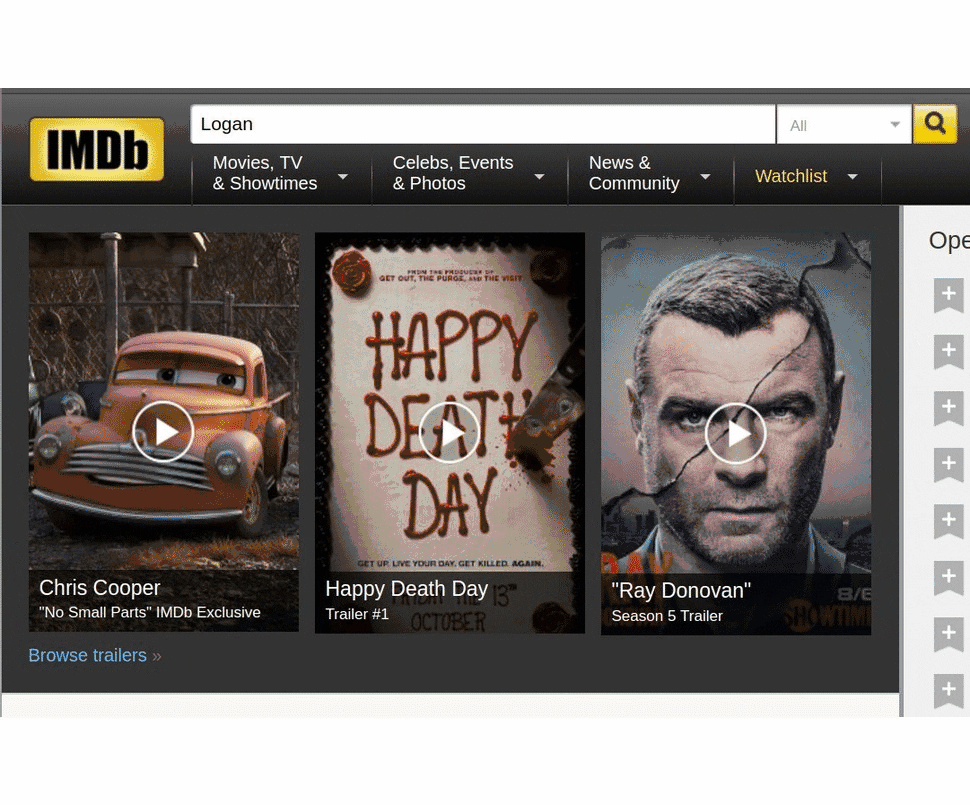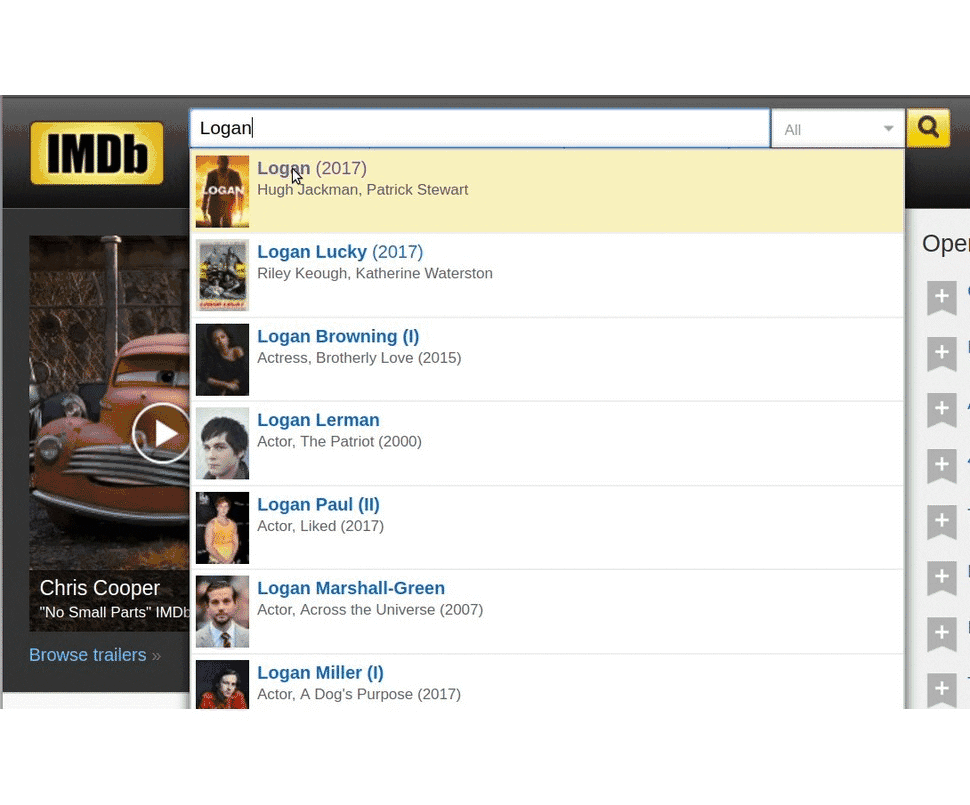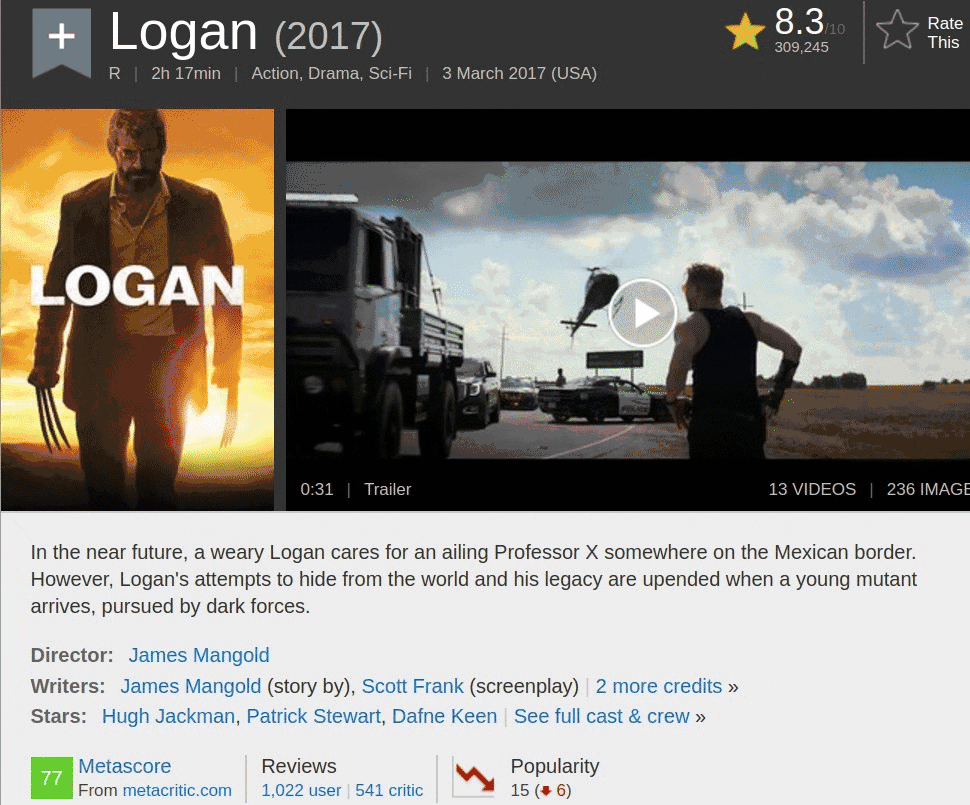
Extraction des données pour un seul film
Nous pouvons accéder au premier conteneur, qui contient des informations sur un seul film, en utilisant la notation de liste sur movie_containers.
first_movie = movie_containers[0]
first_movie<div class="lister-item mode-advanced">
<div class="lister-top-right">
<div class="ribbonize" data-caller="filmosearch" data-tconst="tt3315342"></div>
</div>
<div class="lister-item-image float-left">
<a href="/title/tt3315342/?ref_=adv_li_i"> <img alt="Logan" class="loadlate" data-tconst="tt3315342" height="98" loadlate="https://images-na.ssl-images-amazon.com/images/M/MV5BMjQwODQwNTg4OV5BMl5BanBnXkFtZTgwMTk4MTAzMjI@._V1_UX67_CR0,0,67,98_AL_.jpg" src="https://ia.media-imdb.com/images/G/01/imdb/images/nopicture/large/film-184890147._CB522736516_.png" width="67"/>
</a> </div>
<div class="lister-item-content">
<h3 class="lister-item-header">
<span class="lister-item-index unbold text-primary">1.</span>
<a href="/title/tt3315342/?ref_=adv_li_tt">Logan</a>
<span class="lister-item-year text-muted unbold">(2017)</span>
</h3>
<p class="text-muted ">
<span class="certificate">R</span>
<span class="ghost">|</span>
<span class="runtime">137 min</span>
<span class="ghost">|</span>
<span class="genre">
Action, Drama, Sci-Fi </span>
</p>
<div class="ratings-bar">
<div class="inline-block ratings-imdb-rating" data-value="8.3" name="ir">
<span class="global-sprite rating-star imdb-rating"></span>
<strong>8.3</strong>
</div>
<div class="inline-block ratings-user-rating">
<span class="userRatingValue" data-tconst="tt3315342" id="urv_tt3315342">
<span class="global-sprite rating-star no-rating"></span>
<span class="rate" data-no-rating="Rate this" data-value="0" name="ur">Rate this</span>
</span>
<div class="starBarWidget" id="sb_tt3315342">
<div class="rating rating-list" data-auth="" data-ga-identifier="" data-starbar-class="rating-list" data-user="" id="tt3315342|imdb|8.3|8.3|||search|title" itemprop="aggregateRating" itemscope="" itemtype="https://schema.org/AggregateRating" title="Users rated this 8.3/10 (320,428 votes) - click stars to rate">
<meta content="8.3" itemprop="ratingValue"/>
<meta content="10" itemprop="bestRating"/>
<meta content="320428" itemprop="ratingCount"/>
<span class="rating-bg"> </span>
<span class="rating-imdb " style="width: 116.2px"> </span>
<span class="rating-stars">
<a href="/register/login?why=vote&ref_=tt_ov_rt" rel="nofollow" title="Register or login to rate this title"><span>1</span></a>
<a href="/register/login?why=vote&ref_=tt_ov_rt" rel="nofollow" title="Register or login to rate this title"><span>2</span></a>
<a href="/register/login?why=vote&ref_=tt_ov_rt" rel="nofollow" title="Register or login to rate this title"><span>3</span></a>
<a href="/register/login?why=vote&ref_=tt_ov_rt" rel="nofollow" title="Register or login to rate this title"><span>4</span></a>
<a href="/register/login?why=vote&ref_=tt_ov_rt" rel="nofollow" title="Register or login to rate this title"><span>5</span></a>
<a href="/register/login?why=vote&ref_=tt_ov_rt" rel="nofollow" title="Register or login to rate this title"><span>6</span></a>
<a href="/register/login?why=vote&ref_=tt_ov_rt" rel="nofollow" title="Register or login to rate this title"><span>7</span></a>
<a href="/register/login?why=vote&ref_=tt_ov_rt" rel="nofollow" title="Register or login to rate this title"><span>8</span></a>
<a href="/register/login?why=vote&ref_=tt_ov_rt" rel="nofollow" title="Register or login to rate this title"><span>9</span></a>
<a href="/register/login?why=vote&ref_=tt_ov_rt" rel="nofollow" title="Register or login to rate this title"><span>10</span></a>
</span>
<span class="rating-rating "><span class="value">8.3</span><span class="grey">/</span><span class="grey">10</span></span>
<span class="rating-cancel "><a href="/title/tt3315342/vote?v=X;k=" rel="nofollow" title="Delete"><span>X</span></a></span>
</div>
</div>
</div>
<div class="inline-block ratings-metascore">
<span class="metascore favorable">77 </span>
Metascore
</div>
</div>
<p class="text-muted">
In the near future, a weary Logan cares for an ailing Professor X somewhere on the Mexican border. However, Logan's attempts to hide from the world and his legacy are upended when a young mutant arrives, pursued by dark forces.</p>
<p class="">
Director:
<a href="/name/nm0003506/?ref_=adv_li_dr_0">James Mangold</a>
<span class="ghost">|</span>
Stars:
<a href="/name/nm0413168/?ref_=adv_li_st_0">Hugh Jackman</a>,
<a href="/name/nm0001772/?ref_=adv_li_st_1">Patrick Stewart</a>,
<a href="/name/nm6748436/?ref_=adv_li_st_2">Dafne Keen</a>,
<a href="/name/nm2933542/?ref_=adv_li_st_3">Boyd Holbrook</a>
</p>
<p class="sort-num_votes-visible">
<span class="text-muted">Votes:</span>
<span data-value="320428" name="nv">320,428</span>
<span class="ghost">|</span> <span class="text-muted">Gross:</span>
<span data-value="226,264,245" name="nv">$226.26M</span>
</p>
</div>
</div>Comme vous pouvez le voir, le contenu HTML d'un conteneur est très long. Pour connaître la ligne HTML spécifique à chaque point de données, nous utiliserons à nouveau DevTools.
Le nom du film
Nous commençons par le nom du film et localisons sa ligne HTML correspondante à l'aide de DevTools. Vous pouvez voir que le nom est contenu dans une balise d'ancrage ( <a>). Cette balise est imbriquée dans une balise d'en-tête ( <h3>). La <h3>balise est imbriquée dans une <div>balise. C'est <div>le troisième des divsimbriqués dans le conteneur du premier film. Nous avons stocké le contenu de ce conteneur dans la first_movievariable.
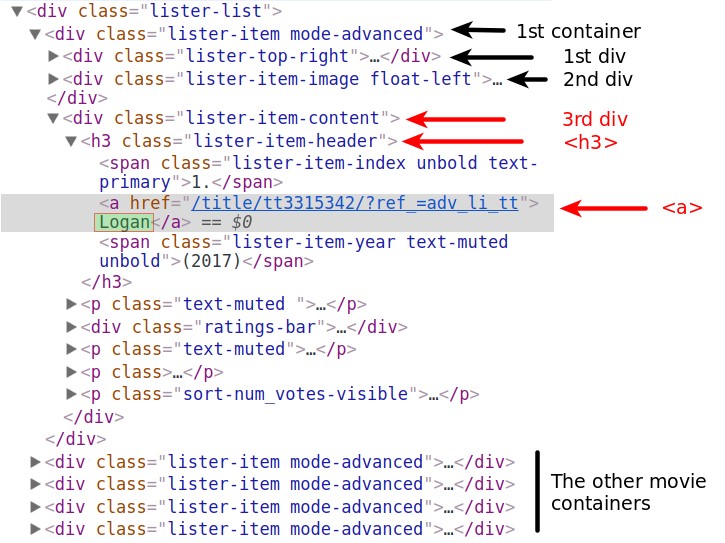
first_movieest un Tag objet , et les différentes balises HTML qu'il contient sont stockées en tant qu'attributs. Nous pouvons y accéder comme nous accéderions à n'importe quel attribut d'un objet Python. Cependant, l'utilisation d'un nom de balise comme attribut ne sélectionnera que la première balise portant ce nom. Si nous exécutons first_movie.div, nous n'obtenons que le contenu de la première divbalise :
first_movie.div<div class="lister-top-right">
<div class="ribbonize" data-caller="filmosearch" data-tconst="tt3315342"></div></div>L'accès à la première balise d'ancrage ( <a>) ne nous amène pas au nom du film. Le premier <a>est quelque part dans le second div:
first_movie.a<a href="/title/tt3315342/?ref_=adv_li_i"> <img alt="Logan" class="loadlate" data-tconst="tt3315342" height="98" loadlate="https://images-na.ssl-images-amazon.com/images/M/MV5BMjQwODQwNTg4OV5BMl5BanBnXkFtZTgwMTk4MTAzMjI@._V1_UX67_CR0,0,67,98_AL_.jpg" src="https://ia.media-imdb.com/images/G/01/imdb/images/nopicture/large/film-184890147._CB522736516_.png" width="67"/></a>Cependant, accéder à la première <h3>balise nous rapproche de très près :
first_movie.h3<h3 class="lister-item-header">
<span class="lister-item-index unbold text-primary">1.</span>
<a href="/title/tt3315342/?ref_=adv_li_tt">Logan</a
><span class="lister-item-year text-muted unbold">(2017)</span>
</h3>À partir de là, nous pouvons utiliser la notation d'attribut pour accéder au premier <a>à l'intérieur de la <h3>balise :
first_movie.h3.a<a href="/title/tt3315342/?ref_=adv_li_tt">Logan</a>Il ne reste plus qu'à accéder au texte à partir de cette <a>balise :
first_name = first_movie.h3.a.text
first_name'Logan'L'année de la sortie du film
Nous passons à l'extraction de l'année. Ces données sont stockées dans la <span>balise sous la <a>qui contient le nom.
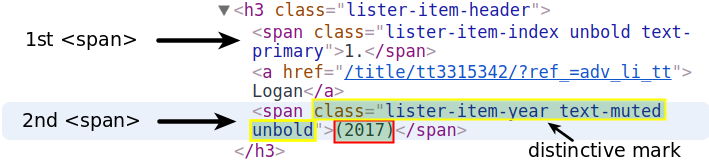
La notation par points n'accédera qu'au premier spanélément. Nous allons rechercher par le signe distinctif du second <span>. Nous utiliserons la find() méthode qui est presque la même que find_all(), sauf qu'elle ne renvoie que la première correspondance. En fait, find()équivaut à find_all(limit = 1). L' limit argument limite la sortie à la première correspondance.
Le signe distinctif est constitué des valeurs lister-item-year text-muted unboldattribuées à l' classattribut. Nous recherchons donc le premier <span>avec ces valeurs dans la <h3>balise :
first_year = first_movie.h3.find('span', class_ = 'lister-item-year text-muted unbold')
first_year<span class="lister-item-year text-muted unbold">(2017)</span>À partir de là, nous accédons simplement au texte en utilisant la notation d'attribut :
first_year = first_year.text
first_year'(2017)'Nous pourrions facilement nettoyer cette sortie et la convertir en un entier. Mais si vous explorez plus de pages, vous remarquerez que pour certains films, l'année prend des valeurs imprévisibles comme (2017)(I) ou (2015)(V). Il est plus efficace de faire le nettoyage après le grattage, quand on connaîtra toutes les valeurs de l'année.
La cote IMDB
Nous nous concentrons maintenant sur l'extraction de la note IMDB du premier film.
Il y a plusieurs façons de le faire, mais nous allons d'abord essayer la plus simple. Si vous inspectez l'évaluation IMDB à l'aide de DevTools, vous remarquerez que l'évaluation est contenue dans une <strong> balise .
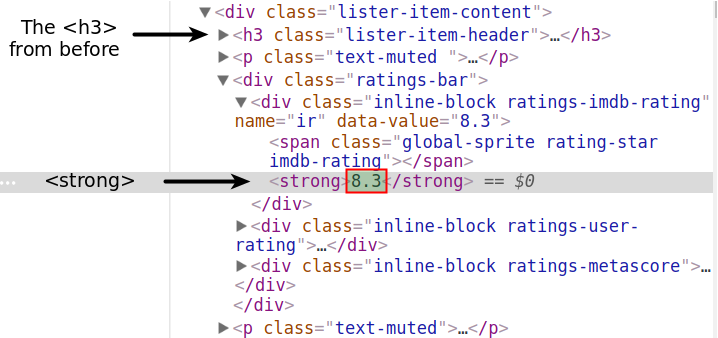
Utilisons la notation d'attribut, et espérons que la première <strong>sera aussi celle qui contiendra la notation.
first_movie.strong<strong>8.3</strong>Génial! Nous allons accéder au texte, le convertir en floattype et l'affecter à la variablefirst_imdb :
first_imdb = float(first_movie.strong.text)
first_imdb8.3Le métascore
Si nous inspectons le Metascore à l'aide de DevTools, nous remarquerons que nous pouvons le trouver dans une spanbalise.
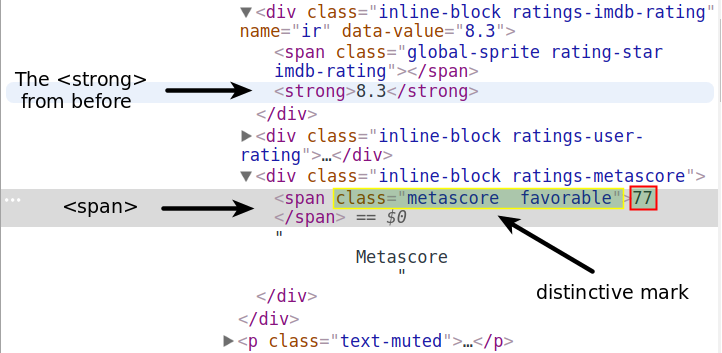
La notation des attributs n'est clairement pas une solution. Il y a beaucoup de <span>balises avant cela. Vous pouvez en voir un juste au-dessus de la <strong>balise. Nous ferions mieux d'utiliser les valeurs distinctives de l' classattribut ( metascore favorable).
Notez que si vous copiez-collez ces valeurs à partir de l'onglet DevTools, il y aura deux espaces blancs entre metascoreet favorable. Assurez-vous qu'il n'y aura qu'un seul caractère d'espacement lorsque vous passerez les valeurs en tant qu'arguments au class_paramètre. Sinon, find()je ne trouverai rien.
first_mscore = first_movie.find('span', class_ = 'metascore favorable')
first_mscore = int(first_mscore.text)
print(first_mscore)77La favorablevaleur indique un Metascore élevé et définit la couleur d'arrière-plan de l'évaluation sur le vert. Les deux autres valeurs possibles sont unfavorableet mixed. Ce qui est spécifique à toutes les évaluations Metascore n'est cependant que la metascorevaleur. C'est celui que nous allons utiliser lorsque nous écrirons le script pour la page entière.
Le nombre de voix
Le nombre de votes est contenu dans une <span>balise. Sa marque distinctive est un nameattribut à valeur nv.

L' nameattribut est différent de l' classattribut. En utilisant BeautifulSoup, nous pouvons accéder aux éléments par n'importe quel attribut. Les fonctions find()et find_all()ont un paramètre nommé attrs. À cela, nous pouvons passer les attributs et les valeurs que nous recherchons sous forme de dictionnaire :
first_votes = first_movie.find('span', attrs = {'name':'nv'})
first_votes<span data-value="320428" name="nv">320,428</span>Nous pourrions utiliser la .textnotation pour accéder au <span>contenu de la balise. Ce serait mieux si nous accédions à la valeur de l' data-valueattribut. De cette façon, nous pouvons convertir le point de données extrait en un intsans avoir à supprimer une virgule.
Vous pouvez traiter un Tagobjet comme un dictionnaire. Les attributs HTML sont les clés du dictionnaire. Les valeurs des attributs HTML sont les valeurs des clés du dictionnaire. Voici comment nous pouvons accéder à la valeur de l' data-valueattribut :
first_votes['data-value']'320428'Convertissons cette valeur en un entier et affectons-la àfirst_votes :
first_votes = int(first_votes['data-value'])C'est ça! Nous sommes maintenant en mesure d'écrire facilement un script pour gratter une seule page.
Le script pour une seule page
Avant de reconstituer ce que nous avons fait jusqu'à présent, nous devons nous assurer que nous extrairons les données uniquement des conteneurs qui ont un Metascore.
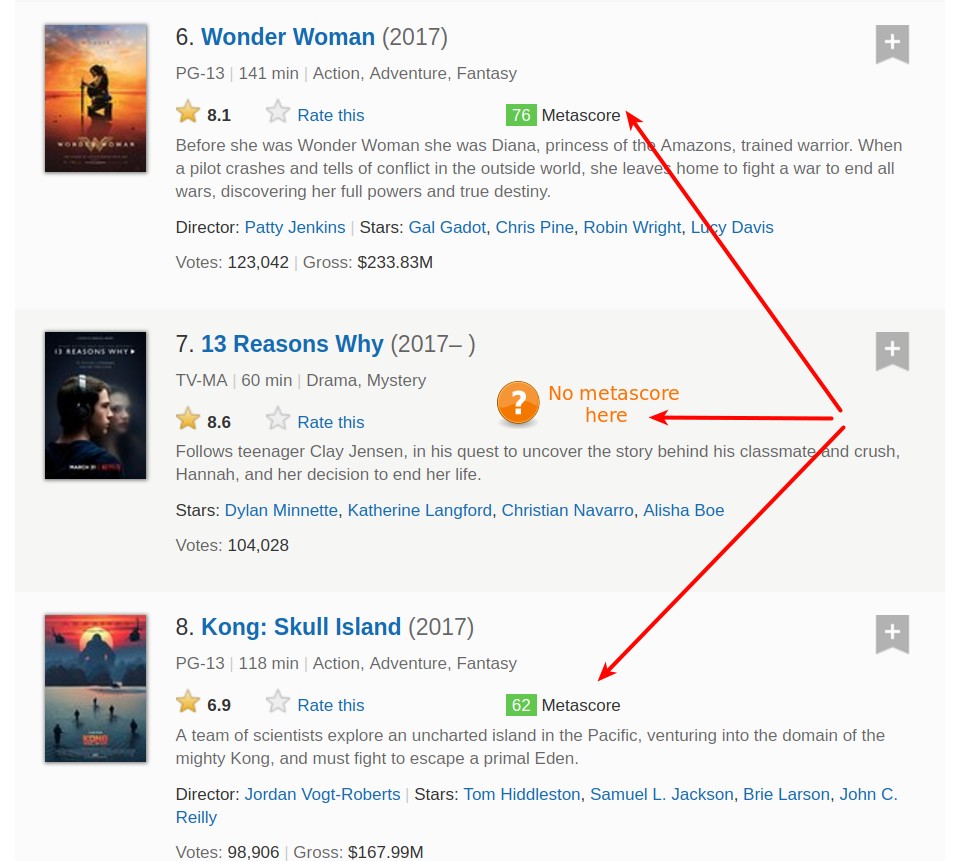
Nous devons ajouter une condition pour ignorer les films sans Metascore.
En utilisant à nouveau DevTools, nous voyons que la section Metascore est contenue dans une <div>balise. L' classattribut a deux valeurs : inline-blocket ratings-metascore. Le distinctif est clairement ratings-metascore.
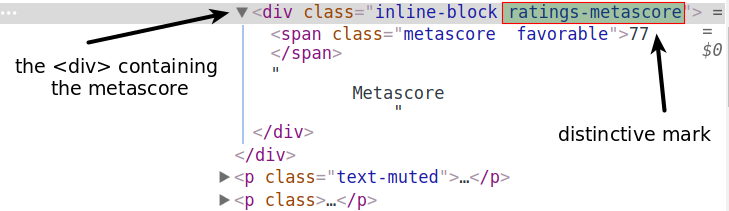
Nous pouvons utiliser find()pour rechercher dans chaque conteneur de film un divayant cette marque distincte. Lorsqu'il find()ne trouve rien, il renvoie un Noneobjet. Nous pouvons utiliser ce résultat dans une ifinstruction pour contrôler si un film est gratté.
Regardons sur la page Web pour rechercher un conteneur de film qui n'a pas de Metascore, et voir ce qui find()revient.
Important : lorsque j'ai exécuté le code suivant, le huitième conteneur n'avait pas de Metascore. Cependant, c'est une cible mouvante, car le nombre de votes change constamment pour chaque film. Pour obtenir les mêmes résultats que j'ai fait dans la cellule de code démonstrative suivante, vous devez rechercher un conteneur qui n'a pas de métascore au moment où vous exécutez le code.
eighth_movie_mscore = movie_containers[7].find('div', class_ = 'ratings-metascore')
type(eighth_movie_mscore)NoneTypeRassemblons maintenant le code ci-dessus, et compressons-le autant que possible, mais seulement dans la mesure où il est encore facilement lisible. Dans le bloc de code suivant, nous :
- Déclarez certaines
listvariables pour avoir quelque chose dans lequel stocker les données extraites. - Parcourez chaque conteneur dans
movie_containers(la variable qui contient les 50 conteneurs de films). - Extrayez les points de données d'intérêt uniquement si le conteneur a un Metascore.
# Lists to store the scraped data in
names = []
years = []
imdb_ratings = []
metascores = []
votes = []
# Extract data from individual movie container
for container in movie_containers:
# If the movie has Metascore, then extract:
if container.find('div', class_ = 'ratings-metascore') is not None:
# The name
name = container.h3.a.text
names.append(name)
# The year
year = container.h3.find('span', class_ = 'lister-item-year').text
years.append(year)
# The IMDB rating
imdb = float(container.strong.text)
imdb_ratings.append(imdb)
# The Metascore
m_score = container.find('span', class_ = 'metascore').text
metascores.append(int(m_score))
# The number of votes
vote = container.find('span', attrs = {'name':'nv'})['data-value']
votes.append(int(vote))Vérifions les données collectées jusqu'à présent. Pandas nous permet de voir facilement si nous avons gratté nos données avec succès.
import pandas as pd
test_df = pd.DataFrame({'movie': names,
'year': years,
'imdb': imdb_ratings,
'metascore': metascores,
'votes': votes
})
print(test_df.info())
test_df<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32 entries, 0 to 31
Data columns (total 5 columns):
imdb 32 non-null float64
metascore 32 non-null int64
movie 32 non-null object
votes 32 non-null int64
year 32 non-null object
dtypes: float64(1), int64(2), object(2)
memory usage: 1.3+ KB
NoneTout s'est déroulé comme prévu !
En passant, si vous exécutez le code à partir d'un pays où l'anglais n'est pas la langue principale, il est très probable que vous obtiendrez certains des noms de films traduits dans la langue principale de ce pays.
Très probablement, cela se produit parce que le serveur déduit votre emplacement à partir de votre adresse IP. Même si vous vous trouvez dans un pays où l'anglais est la langue principale, vous pouvez toujours obtenir du contenu traduit. Cela peut se produire si vous utilisez un VPN pendant que vous effectuez les GETdemandes.
Si vous rencontrez ce problème, transmettez les valeurs suivantes au headersparamètre de la get()fonction :
headers = {"Accept-Language": "en-US, en;q=0.5"}Cela communiquera au serveur quelque chose comme « Je veux le contenu linguistique en anglais américain (en-US). Si en-US n'est pas disponible, d'autres types d'anglais (en) conviendraient également (mais pas autant que en-US). ». Le qparamètre indique dans quelle mesure nous préférons une certaine langue. Si non spécifié, les valeurs sont définies 1par défaut, comme dans le cas de en-US. Vous pouvez en savoir plus à ce sujet ici .
Commençons maintenant à créer le script pour toutes les pages que nous voulons gratter.
Le script pour plusieurs pages
Le grattage de plusieurs pages est un peu plus difficile. Nous allons nous appuyer sur notre script d'une page en faisant trois autres choses :
- Faire toutes les demandes que nous voulons depuis la boucle.
- Contrôler le débit de la boucle pour éviter de bombarder le serveur de requêtes.
- Surveillance de la boucle pendant son exécution.
Nous gratterons les 4 premières pages de chaque année dans l'intervalle 2000-2017. 4 pages pour chacune des 18 années font un total de 72 pages. Chaque page contient 50 films, nous allons donc récupérer les données de 3600 films au maximum. Mais tous les films n'ont pas de Metascore, donc le nombre sera inférieur à cela. Même ainsi, nous sommes toujours très susceptibles d'obtenir des données pour plus de 2000 films.
Modification des paramètres de l'URL
Comme indiqué précédemment, les URL suivent une certaine logique lorsque les pages Web changent.

Au fur et à mesure que nous effectuons les requêtes, nous n'aurons qu'à faire varier les valeurs de seulement deux paramètres de l'URL : le release_dateparamètre et page. Préparons les valeurs dont nous aurons besoin pour la prochaine boucle. Dans la cellule de code suivante, nous allons :
- Créez une liste appelée
pages, et remplissez-la avec les chaînes correspondant aux 4 premières pages. - Créez une liste appelée
years_urlet remplissez-la avec les chaînes correspondant aux années 2000-2017.
pages = [str(i) for i in range(1,5)]
years_url = [str(i) for i in range(2000,2018)]Contrôler le crawl-rate
Contrôler le taux de crawl est bénéfique pour nous, et pour le site web que nous grattons. Si nous évitons de marteler le serveur avec des dizaines de requêtes par seconde, nous risquons beaucoup moins de voir notre adresse IP bannie. Nous évitons également de perturber l'activité du site Web que nous récupérons en permettant au serveur de répondre également aux demandes des autres utilisateurs.
Nous contrôlerons le taux de la boucle en utilisant la sleep() fonction du time module Python . sleep()suspendra l'exécution de la boucle pendant un nombre de secondes spécifié.
Pour imiter le comportement humain, nous allons faire varier le temps d'attente entre les requêtes en utilisant la randint() fonction du random module Python . randint()génère aléatoirement des entiers dans un intervalle spécifié.
Pour l'instant, importons simplement ces deux fonctions pour éviter la surpopulation dans la cellule de code contenant notre principale sleep from loop
from time import sleep
from random
import randintSurveillance de la boucle telle qu'elle est toujours en cours
Étant donné que nous récupérons 72 pages, ce serait bien si nous pouvions trouver un moyen de surveiller le processus de grattage tel qu'il est toujours en cours. Cette fonctionnalité est certainement facultative, mais elle peut être très utile dans le processus de test et de débogage. De plus, plus le nombre de pages est élevé, plus la surveillance devient utile. Si vous allez gratter des centaines ou des milliers de pages Web en une seule exécution de code, je dirais que cette fonctionnalité devient un must.
Pour notre script, nous utiliserons cette fonctionnalité et surveillerons les paramètres suivants :
- La fréquence (vitesse) des requêtes , nous nous assurons donc que notre programme ne surcharge pas le serveur.
- Le nombre de requêtes , afin que nous puissions arrêter la boucle au cas où le nombre de requêtes attendues serait dépassé.
- Le code d'état de nos requêtes, nous nous assurons donc que le serveur renvoie les bonnes réponses.
Pour obtenir une valeur de fréquence, nous diviserons le nombre de requêtes par le temps écoulé depuis la première requête. Ceci est similaire au calcul de la vitesse d'une voiture - nous divisons la distance par le temps nécessaire pour couvrir cette distance. Expérimentons d'abord cette technique de surveillance à petite échelle. Dans la cellule de code suivante, nous allons :
- Définissez une heure de début à l'aide de la
time()fonction dutimemodule et attribuez la valeur àstart_time. - Attribuez 0 à la variable
requestsque nous utiliserons pour compter le nombre de requêtes. - Démarrez une boucle, puis à chaque itération :
- Simuler une demande.
- Incrémentez le nombre de requêtes de 1.
- Mettez la boucle en pause pendant un intervalle de temps compris entre 8 et 15 secondes.
- Calculez le temps écoulé depuis la première demande et attribuez la valeur à
elapsed_time. - Imprimer le nombre de demandes et la fréquence.
from time import timestart_time = time()
requests = 0
for _ in range(5):
# A request would go here
requests += 1
sleep(randint(1,3))
elapsed_time = time() - start_time
print('Request: {}; Frequency: {} requests/s'.format(requests, requests/elapsed_time))Request: 1; Frequency: 0.49947650463238624 requests/s
Request: 2; Frequency: 0.4996998027377252 requests/s
Request: 3; Frequency: 0.5995400143227362 requests/s
Request: 4; Frequency: 0.4997272043465967 requests/s
Request: 5; Frequency: 0.4543451628627026 requests/sPuisque nous allons faire 72 requêtes, notre travail semblera un peu désordonné au fur et à mesure que la sortie s'accumule. Pour éviter cela, nous effacerons la sortie après chaque itération et la remplacerons par des informations sur la requête la plus récente. Pour ce faire, nous utiliserons la clear_output()fonction du core.display module IPython . Nous allons définir le waitparamètre de clear_output()pour Trueattendre avec le remplacement de la sortie actuelle jusqu'à ce qu'une nouvelle sortie apparaisse.
from IPython.core.display import clear_output
start_time = time()requests = 0
for _ in range(5):
# A request would go here
requests += 1
sleep(randint(1,3))
current_time = time()
elapsed_time = current_time - start_time
print('Request: {}; Frequency: {} requests/s'.format(requests, requests/elapsed_time))
clear_output(wait = True)Request: 5; Frequency: 0.6240351700607663 requests/sLa sortie ci-dessus est la sortie que vous verrez une fois la boucle exécutée. Voici à quoi cela ressemble pendant qu'il fonctionne

Pour surveiller le code d'état, nous allons configurer le programme pour qu'il nous avertisse s'il y a quelque chose qui ne va pas. Une requête réussie est indiquée par un code d'état de 200. Nous utiliserons la warn() fonction du warnings module pour lancer un avertissement si le code d'état n'est pas 200.
from warnings import warnwarn("Warning Simulation")/Users/joshuadevlin/.virtualenvs/everday-ds/lib/python3.4/site-packages/ipykernel/__main__.py:3:
UserWarning: Warning Simulation app.launch_new_instance()Nous avons choisi un avertissement plutôt que de rompre la boucle car il y a de bonnes chances que nous récupérions suffisamment de données, même si certaines des demandes échouent. Nous ne romprons la boucle que si le nombre de requêtes est supérieur à celui prévu.
Rassembler le tout
Rassemblons maintenant tout ce que nous avons fait jusqu'à présent ! Dans la cellule de code suivante, nous commençons par :
- Redéclarer les variables des listes pour qu'elles redeviennent vides.
- Préparation du suivi de la boucle.
Alors bien:
- Parcourez la
years_urlliste pour faire varier lerelease_dateparamètre de l'URL. - Pour chaque élément de
years_url, parcourez lapagesliste pour faire varier lepageparamètre de l'URL. - Faites les
GETrequêtes dans lapagesboucle (et donnez auheadersparamètre la bonne valeur pour vous assurer que nous n'obtenons que du contenu en anglais). - Mettez la boucle en pause pendant un intervalle de temps compris entre 8 et 15 secondes.
- Surveillez chaque demande comme indiqué précédemment.
- Lancer un avertissement pour les codes d'état non-200.
- Brisez la boucle si le nombre de requêtes est supérieur à celui prévu.
- Convertissez le
responsecontenu HTML de en unBeautifulSoupobjet. - Extrayez tous les conteneurs de films de cet
BeautifulSoupobjet. - Parcourez tous ces conteneurs.
- Extrayez les données si un conteneur a un Metascore.
# Redeclaring the lists to store data in
names = []
years = []
imdb_ratings = []
metascores = []
votes = []
# Preparing the monitoring of the loop
start_time = time()
requests = 0
# For every year in the interval 2000-2017
for year_url in years_url:
# For every page in the interval 1-4
for page in pages:
# Make a get request
response = get('https://www.imdb.com/search/title?release_date=' + year_url +
'&sort=num_votes,desc&page=' + page, headers = headers)
# Pause the loop
sleep(randint(8,15))
# Monitor the requests
requests += 1
elapsed_time = time() - start_time
print('Request:{}; Frequency: {} requests/s'.format(requests, requests/elapsed_time))
clear_output(wait = True)
# Throw a warning for non-200 status codes
if response.status_code != 200:
warn('Request: {}; Status code: {}'.format(requests, response.status_code))
# Break the loop if the number of requests is greater than expected
if requests > 72:
warn('Number of requests was greater than expected.')
break
# Parse the content of the request with BeautifulSoup
page_html = BeautifulSoup(response.text, 'html.parser')
# Select all the 50 movie containers from a single page
mv_containers = page_html.find_all('div', class_ = 'lister-item mode-advanced')
# For every movie of these 50
for container in mv_containers:
# If the movie has a Metascore, then:
if container.find('div', class_ = 'ratings-metascore') is not None:
# Scrape the name
name = container.h3.a.text
names.append(name)
# Scrape the year
year = container.h3.find('span', class_ = 'lister-item-year').text
years.append(year)
# Scrape the IMDB rating
imdb = float(container.strong.text)
imdb_ratings.append(imdb)
# Scrape the Metascore
m_score = container.find('span', class_ = 'metascore').text
metascores.append(int(m_score))
# Scrape the number of votes
vote = container.find('span', attrs = {'name':'nv'})['data-value']
votes.append(int(vote))Request:72; Frequency: 0.07928964663062842 requests/sAgréable! Le grattage semble avoir parfaitement fonctionné. Le script a duré environ 16 minutes.
Fusionnons maintenant les données dans un pandas DataFramepour examiner ce que nous avons réussi à gratter. Si tout se passe comme prévu, nous pouvons passer au nettoyage des données pour les préparer à l'analyse.
Examen des données grattées
Dans le bloc de code suivant, nous :
- Fusionner les données dans un pandas
DataFrame. - Imprimez quelques informations sur le nouveau fichier
DataFrame. - Afficher les 10 premières entrées.
movie_ratings = pd.DataFrame({'movie': names,
'year': years,
'imdb': imdb_ratings,
'metascore': metascores,
'votes': votes
})
print(movie_ratings.info())
movie_ratings.head(10)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2862 entries, 0 to 2861
Data columns (total 5 columns):
imdb 2862 non-null float64
metascore 2862 non-null int64
movie 2862 non-null object
votes 2862 non-null int64
year 2862 non-null object
dtypes: float64(1), int64(2), object(2)
memory usage: 111.9+ KB
NoneLa sortie des info()émissions, nous avons collecté des données pour plus de 2000 films. Nous pouvons également voir qu'il n'y a aucune nullvaleur dans notre ensemble de données.
J'ai vérifié les notes de ces 10 premiers films sur le site Web de l'IMDB. Ils avaient tous raison. Vous voudrez peut-être faire la même chose vous-même.
Nous pouvons procéder en toute sécurité au nettoyage des données.
Nettoyer les données grattées
Nous allons nettoyer les données grattées avec deux objectifs en tête : tracer la distribution des notes IMDB et Metascore et partager l'ensemble de données. Par conséquent, notre nettoyage de données consistera à :
- Réorganisation des colonnes.
- Nettoyer la
yearcolonne et convertir les valeurs en nombres entiers. - Vérifier les valeurs de notation extrêmes pour déterminer si toutes les notations se situent dans les intervalles attendus.
- Normaliser l'un des types d'évaluation (ou les deux) pour générer un histogramme comparatif .
Commençons par réorganiser les colonnes :
movie_ratings = movie_ratings[['movie', 'year', 'imdb', 'metascore', 'votes']]
movie_ratings.head()Convertissons maintenant toutes les valeurs de la yearcolonne en nombres entiers.
À l'heure actuelle, toutes les valeurs sont du objecttype. Pour éviter ValueErrorslors de la conversion, nous voulons que les valeurs soient composées uniquement de nombres de 0 à 9.
Examinons les valeurs uniques de la yearcolonne. Cela nous aide à avoir une idée de ce que nous pourrions faire pour effectuer les conversions que nous voulons. Pour voir toutes les valeurs uniques, nous utiliserons la unique()méthode :
movie_ratings['year'].unique()array(['(2000)', '(I) (2000)', '(2001)', '(I) (2001)', '(2002)',
'(I) (2002)', '(2003)', '(I) (2003)', '(2004)', '(I) (2004)',
'(2005)', '(I) (2005)', '(2006)', '(I) (2006)', '(2007)',
'(I) (2007)', '(2008)', '(I) (2008)', '(2009)', '(I) (2009)',
'(II) (2009)', '(2010)', '(I) (2010)', '(II) (2010)', '(2011)',
'(I) (2011)', '(IV) (2011)', '(2012)', '(I) (2012)', '(II) (2012)',
'(2013)', '(I) (2013)', '(II) (2013)', '(2014)', '(I) (2014)',
'(II) (2014)', '(III) (2014)', '(2015)', '(I) (2015)',
'(II) (2015)', '(VI) (2015)', '(III) (2015)', '(2016)',
'(II) (2016)', '(I) (2016)', '(IX) (2016)', '(V) (2016)', '(2017)',
'(I) (2017)', '(III) (2017)', '(IV) (2017)'], dtype=object)En comptant de la fin vers le début, nous pouvons voir que les années sont toujours situées du cinquième caractère au deuxième. Nous utiliserons la .str() méthode pour sélectionner uniquement cet intervalle. Nous allons également convertir le résultat en un entier en utilisant la astype() méthode :
movie_ratings.loc[:, 'year'] = movie_ratings['year'].str[-5:-1].astype(int)Visualisons les 3 premières valeurs de la yearcolonne pour une vérification rapide. Nous pouvons également voir le type des valeurs sur la dernière ligne de la sortie :
movie_ratings['year'].head(3)0 2000
1 2000
2 2000
Name: year, dtype: int64Nous allons maintenant vérifier les valeurs minimales et maximales de chaque type de notation. Nous pouvons le faire très rapidement en utilisant la describe() méthode des pandas . Lorsqu'elle est appliquée sur un DataFrame, cette méthode renvoie diverses statistiques descriptives pour chaque colonne numérique du DataFrame. Dans la ligne de code suivante, nous sélectionnons uniquement les lignes qui décrivent les valeurs minimales et maximales, et uniquement les colonnes qui décrivent les évaluations IMDB et les métascores.
movie_ratings.describe().loc[['min', 'max'], ['imdb', 'metascore']]Il n'y a pas de valeurs aberrantes inattendues.
D'après les valeurs ci-dessus, vous pouvez voir que les deux évaluations ont des échelles différentes. Pour pouvoir tracer les deux distributions sur un même graphe, il va falloir les ramener à la même échelle. Normalisons la imdbcolonne à une échelle de 100 points.
Nous multiplierons chaque note IMDB par 10, puis nous effectuerons une vérification rapide en examinant les 3 premières lignes :
movie_ratings['n_imdb'] = movie_ratings['imdb'] * 10
movie_ratings.head(3)Agréable! Nous sommes maintenant en mesure de sauvegarder cet ensemble de données localement, afin de pouvoir le partager plus facilement avec d'autres. Je l'ai déjà partagé publiquement sur mon profil GitHub . Il existe d'autres endroits où vous pouvez partager un ensemble de données, comme Kaggle ou Dataworld .
Alors gardons-le :
movie_ratings.to_csv('movie_ratings.csv')En remarque, je recommande fortement d'enregistrer l'ensemble de données gratté avant de quitter (ou de redémarrer) le noyau de votre ordinateur portable. De cette façon, vous n'aurez à importer l'ensemble de données que lorsque vous reprendrez votre travail et vous n'aurez pas à réexécuter le script de grattage. Cela devient extrêmement utile si vous grattez des centaines ou des milliers de pages Web.
Enfin, traçons les distributions !
Tracer et analyser les distributions
Dans la cellule de code suivante, nous :
- Importez le
matplotlib.pyplotsous - module. - Exécutez la magie Jupyter
%matplotlibpour activer le mode matplotlib de Jupyter et ajoutezinlinepour que nos graphiques s'affichent dans le cahier. - Créez un
figureobjet avec 3axes. - Tracez la distribution de chaque note non normalisée sur un individu
ax. - Tracez les distributions normalisées des deux cotes sur le même
ax. - Cachez les épines supérieures et droites de tous les trois
axes.
import matplotlib.pyplot as plt
fig, axes = plt.subplots(nrows = 1, ncols = 3, figsize = (16,4))
ax1, ax2, ax3 = fig.axes
ax1.hist(movie_ratings['imdb'], bins = 10, range = (0,10)) # bin range = 1
ax1.set_title('IMDB rating')
ax2.hist(movie_ratings['metascore'], bins = 10, range = (0,100)) # bin range = 10
ax2.set_title('Metascore')
ax3.hist(movie_ratings['n_imdb'], bins = 10, range = (0,100), histtype = 'step')
ax3.hist(movie_ratings['metascore'], bins = 10, range = (0,100), histtype = 'step')
ax3.legend(loc = 'upper left')
ax3.set_title('The Two Normalized Distributions')
for ax in fig.axes:
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.show()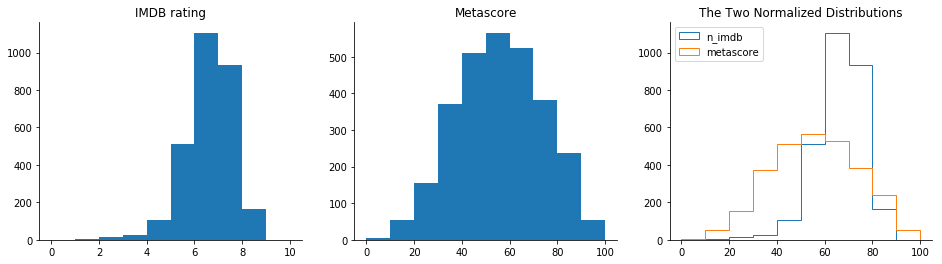
En partant de l' histogramme IMDB , on peut voir que la plupart des notes sont comprises entre 6 et 8. Il y a peu de films avec une note supérieure à 8, et encore moins avec une note inférieure à 4. Cela indique à la fois de très bons films et de très mauvais films sont plus rares.
La distribution des notes Metascore ressemble à une distribution normale - la plupart des notes sont moyennes, culminant à la valeur d'environ 50. À partir de ce pic, les fréquences diminuent progressivement vers des valeurs de notes extrêmes. Selon cette répartition, il y a effectivement moins de très bons et de très mauvais films, mais pas si peu que l'indiquent les notes IMDB.
Sur le graphique comparatif, il est plus clair que la distribution IMDB est fortement biaisée vers la partie supérieure des notes moyennes, tandis que les notes Metascore semblent avoir une distribution beaucoup plus équilibrée.
Quelle pourrait être la raison de ce décalage dans la distribution IMDB ? Une hypothèse est que de nombreux utilisateurs ont tendance à avoir une méthode binaire d'évaluation des films. S'ils aiment le film, ils lui donnent un 10. S'ils n'aiment pas le film, ils lui donnent une très petite note, ou ils ne prennent pas la peine de noter le film. C'est un problème intéressant qui mérite d'être exploré plus en détail.
Prochaines étapes
Nous avons parcouru un long chemin depuis la demande du contenu d'une seule page Web jusqu'à l'analyse des notes de plus de 2000 films. Vous devez maintenant savoir comment scraper de nombreuses pages Web avec la même structure HTML et URL.
Pour tirer parti de ce que nous avons appris, voici quelques étapes suivantes à considérer :
- Grattez les données pour différents intervalles de temps et de pages.
- Grattez des données supplémentaires sur les films.
- Trouvez un autre site Web pour gratter quelque chose qui vous intéresse. Par exemple, vous pouvez extraire des données sur les ordinateurs portables pour voir comment les prix varient dans le temps.



Commentaires
Enregistrer un commentaire