SYSTEME DE RECONNAISSANCE FACIALE AVEC PYTHON
Dans ce didacticiel, vous apprendrez à utiliser OpenCV pour effectuer une reconnaissance faciale. Pour construire notre système de reconnaissance faciale, nous allons d'abord effectuer la détection des visages, extraire les intégrations de visage de chaque visage à l'aide d'un apprentissage en profondeur, former un modèle de reconnaissance faciale sur les intégrations, puis enfin reconnaître les visages dans les images et les flux vidéo avec OpenCV.
Vous pouvez bien sûr échanger votre propre ensemble de données de visages ! Tout ce que vous avez à faire est de suivre ma structure de répertoires pour insérer vos propres images de visage.
En prime, j'ai également inclus comment étiqueter les visages "inconnus" qui ne peuvent pas être classés avec suffisamment de confiance.
Pour savoir comment effectuer la reconnaissance faciale OpenCV, continuez à lire !
- Mise à jour juillet 2021 : Ajout d'une section sur les méthodes alternatives de reconnaissance faciale à considérer, y compris la façon dont les réseaux siamois peuvent être utilisés pour la reconnaissance faciale.
Dans le didacticiel d'aujourd'hui, vous apprendrez à effectuer une reconnaissance faciale à l'aide de la bibliothèque OpenCV.
Eh bien, gardez à l'esprit que le message de reconnaissance faciale dlib s'appuyait sur deux bibliothèques externes importantes :
- dlib (évidemment)
- face_recognition (qui est un ensemble d'utilitaires de reconnaissance faciale facile à utiliser qui entoure dlib)
Bien que nous ayons utilisé OpenCV pour faciliter la reconnaissance faciale, OpenCV lui-même n'était pas responsable de l'identification des visages.
Dans le tutoriel d'aujourd'hui, nous allons apprendre comment nous pouvons appliquer ensemble l'apprentissage en profondeur et OpenCV (sans autres bibliothèques que scikit-learn) pour :
- Détecter les visages
- Calculer des plongements de visage 128-d pour quantifier un visage
- Former une machine à vecteurs de support (SVM) au-dessus des incorporations
- Reconnaître les visages dans les images et les flux vidéo
Toutes ces tâches seront accomplies avec OpenCV, nous permettant d'obtenir un pipeline de reconnaissance faciale OpenCV "pur".
Comment fonctionne la reconnaissance faciale d'OpenCV
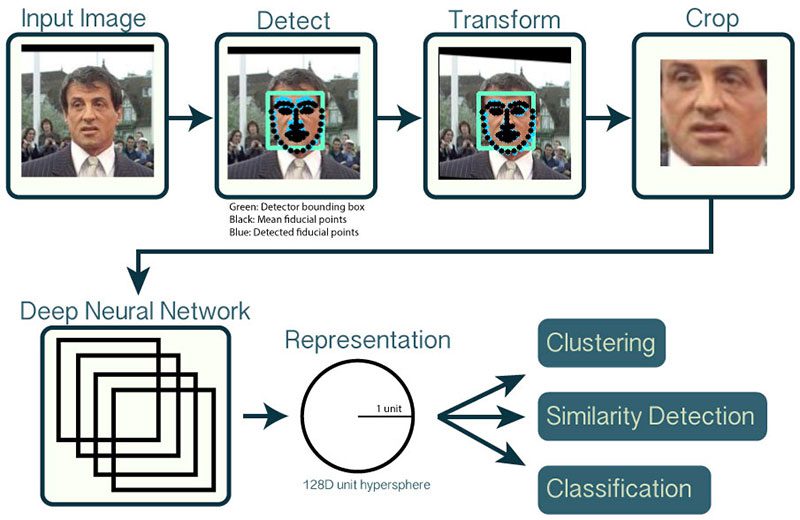
Afin de construire notre pipeline de reconnaissance faciale OpenCV, nous appliquerons l'apprentissage en profondeur en deux étapes clés :
- Pour appliquer la détection de visage , qui détecte la présence et l'emplacement d'un visage dans une image, mais ne l'identifie pas
- Pour extraire les vecteurs de caractéristiques 128-d (appelés "embeddings") qui quantifient chaque visage dans une image
J'ai déjà expliqué comment fonctionne la détection de visage d'OpenCV , veuillez donc vous y référer si vous n'avez pas détecté de visages auparavant.
Le modèle responsable de la quantification réelle de chaque visage dans une image provient du projet OpenFace , une implémentation Python et Torch de la reconnaissance faciale avec apprentissage en profondeur. Cette implémentation provient de la publication CVPR 2015 de Schroff et al., FaceNet: A Unified Embedding for Face Recognition and Clustering .
L'examen de l'ensemble de la mise en œuvre de FaceNet n'entre pas dans le cadre de ce didacticiel, mais l'essentiel du pipeline peut être vu dans la figure 1 ci-dessus.
Tout d'abord, nous entrons une image ou une image vidéo dans notre pipeline de reconnaissance faciale. Étant donné l'image d'entrée, nous appliquons la détection de visage pour détecter l'emplacement d'un visage dans l'image.
En option, nous pouvons calculer des repères faciaux , ce qui nous permet de prétraiter et d'aligner le visage .
L'alignement des visages, comme son nom l'indique, consiste à (1) identifier la structure géométrique des visages et (2) tenter d'obtenir un alignement canonique du visage basé sur la translation, la rotation et l'échelle.
Bien qu'il soit facultatif, il a été démontré que l'alignement des visages augmente la précision de la reconnaissance faciale dans certains pipelines.
Après avoir (éventuellement) appliqué l'alignement et le recadrage des visages, nous passons le visage d'entrée à travers notre réseau de neurones profond :
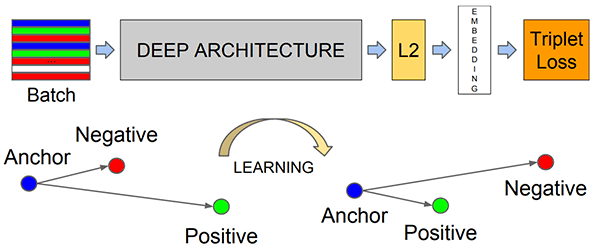
Le modèle d'apprentissage en profondeur FaceNet calcule une incorporation de 128 d qui quantifie le visage lui-même.
Mais comment le réseau calcule-t-il réellement l'intégration du visage ?
La réponse réside dans le processus de formation lui-même, notamment :
- Les données d'entrée sur le réseau
- La fonction de perte de triplet
Pour entraîner un modèle de reconnaissance faciale avec le deep learning, chaque lot de données d'entrée comprend trois images :
- L' ancre
- L' image positive
- L' image négative
L'ancre est notre visage actuel et a l'identité A .
La deuxième image est notre image positive — cette image contient également un visage de la personne A .
L'image négative, en revanche, n'a pas la même identité , et pourrait appartenir à la personne B , C , ou même Y !
Le fait est que l'ancre et l'image positive appartiennent toutes deux à la même personne/visage alors que l'image négative ne contient pas le même visage.
Le réseau de neurones calcule les incorporations 128-d pour chaque face, puis ajuste les poids du réseau (via la fonction de perte de triplet) de telle sorte que :
- Les plongements 128-d de l'ancre et de l'image positive sont plus proches l'un de l'autre
- Tout en repoussant les intégrations du père de l'image négative
De cette manière, le réseau est capable d'apprendre à quantifier les visages et de renvoyer des incorporations très robustes et discriminantes adaptées à la reconnaissance faciale.
Et de plus, nous pouvons réellement réutiliser le modèle OpenFace pour nos propres applications sans avoir à le former explicitement !
Même si le modèle d'apprentissage en profondeur que nous utilisons aujourd'hui n'a (très probablement) jamais vu les visages que nous sommes sur le point de traverser, le modèle sera toujours capable de calculer les intégrations pour chaque visage - idéalement, ces intégrations de visage seront suffisamment différent de sorte que nous pouvons former un classificateur d'apprentissage automatique "standard" (SVM, classificateur SGD, Random Forest, etc.) au-dessus des incorporations de visage, et donc obtenir notre pipeline de reconnaissance faciale OpenCV.
Si vous souhaitez en savoir plus sur les détails entourant la perte de triplets et sur la façon dont elle peut être utilisée pour former un modèle d'intégration de visage, assurez-vous de vous référer à mon article de blog précédent ainsi qu'au Schroff et al. parution .
Notre ensemble de données de reconnaissance faciale

L'ensemble de données que nous utilisons aujourd'hui contient trois personnes :
- Moi-même
- Trisha (ma femme)
- "Inconnu", qui est utilisé pour représenter les visages de personnes que nous ne connaissons pas et que nous souhaitons étiqueter comme tels (ici, je viens d'échantillonner des visages du film Jurassic Park que j'ai utilisé dans un post précédent - vous pouvez insérer votre propre "inconnu " base de données).
Comme je l'ai mentionné dans l'introduction du message de reconnaissance faciale d'aujourd'hui, je viens de me marier le week-end, donc ce message est un "cadeau" pour ma nouvelle femme ?.
Chaque classe contient un total de six images.
Si vous construisez votre propre ensemble de données de reconnaissance faciale , idéalement, je suggérerais d'avoir 10 à 20 images par personne que vous souhaitez reconnaître - assurez-vous de vous référer à la section "Inconvénients, limites et comment obtenir une plus grande précision de reconnaissance faciale" de ce article de blog pour plus de détails.
Structuration du projet
Une fois que vous avez récupéré le zip dans la section "Téléchargements" de cet article, allez-y, décompressez l'archive et naviguez dans le répertoire.
De là, vous pouvez utiliser le
Il y a pas mal de parties mobiles pour ce projet — prenez le temps maintenant de lire attentivement cette section afin de vous familiariser avec tous les fichiers du projet d'aujourd'hui.
Notre projet a quatre répertoires dans le dossier racine :
- base de données/: Contient nos images de visage organisées en sous-dossiers par nom.
- images/: Contient trois images de test que nous utiliserons pour vérifier le fonctionnement de notre modèle.
- face_detection_model/: Contient un modèle d'apprentissage en profondeur Caffe pré-formé fourni par OpenCV pour détecter les visages. Ce modèle détecte et localise les visages dans une image.
- production/: Contient mes fichiers pickle de sortie. Si vous travaillez avec votre propre jeu de données, vous pouvez également y stocker vos fichiers de sortie. Les fichiers de sortie incluent :
- encastrements.pickle: Un fichier sérialisé d'incrustations faciales. Les plongements ont été calculés pour chaque face du jeu de données et sont stockés dans ce fichier.
- le.pickle: Notre encodeur d'étiquettes. Contient les étiquettes de nom des personnes que notre modèle peut reconnaître.
- Reconnaître.pickle: Notre modèle de Machine à Vecteur de Support Linéaire (SVM). Il s'agit d'un modèle d'apprentissage automatique plutôt que d'un modèle d'apprentissage en profondeur et il est responsable de la reconnaissance réelle des visages.
Résumons les cinq fichiers du répertoire racine :
- extract_embeddings.py: Nous examinerons ce fichier à l' étape 1 , qui est responsable de l'utilisation d'un extracteur de fonctionnalités d'apprentissage en profondeur pour générer un vecteur 128-D décrivant un visage. Tous les visages de notre ensemble de données passeront par le réseau de neurones pour générer des incorporations.
- openface_nn4.small2.v1.t7: Un modèle d'apprentissage en profondeur Torch qui produit les incorporations faciales 128-D. Nous utiliserons ce modèle d'apprentissage en profondeur dans les étapes 1, 2 et 3 , ainsi que dans la section Bonus .
- train_model.py: Notre modèle SVM linéaire sera entraîné par ce script à l' étape 2 . Nous allons détecter les visages, extraire les intégrations et ajuster notre modèle SVM aux données d'intégration.
- reconnaître.py: À l'étape 3 , nous reconnaîtrons les visages dans les images. Nous allons détecter les visages, extraire les représentations incorporées et interroger notre modèle SVM pour déterminer qui se trouve dans une image. Nous allons dessiner des cadres autour des visages et annoter chaque cadre avec un nom.
- Reconnaître_vidéo.py: Notre section Bonus décrit comment reconnaître qui se trouve dans les images d'un flux vidéo, tout comme nous l'avons fait à l' étape 3 sur les images statiques.
Passons à la première étape !
Étape 1 : Extraire les représentations vectorielles continues de l'ensemble de données de visage
Maintenant que nous comprenons le fonctionnement de la reconnaissance faciale et que nous avons examiné la structure de notre projet, commençons à créer notre pipeline de reconnaissance faciale OpenCV.
Ouvrez le
Nous importons nos packages requis sur les lignes 2-8 . Vous aurez besoin d'OpenCV et
Ensuite, nous traitons nos arguments de ligne de commande :
- --base de données: Le chemin d'accès à notre ensemble de données d'entrée d'images de visage.
- --encastrements: Le chemin d'accès à notre fichier d'incorporations de sortie. Notre script calculera les incorporations de visages que nous sérialiserons sur le disque.
- --détecteur: Chemin vers le détecteur de visage d'apprentissage en profondeur basé sur Caffe d'OpenCV utilisé pour localiser réellement les visages dans les images.
- --embedding-model: Chemin d'accès au modèle d'intégration OpenCV Deep Learning Torch. Ce modèle nous permettra d' extraire un vecteur d'incorporation faciale 128-D.
- --confiance: Seuil facultatif pour filtrer les détections de visages de la semaine.
Maintenant que nous avons importé nos packages et analysé les arguments de la ligne de commande, chargeons le détecteur de visage et l'intégrateur depuis le disque :
→ Lancer Jupyter Notebook sur Google ColabIci, nous chargeons le détecteur de visage et l'intégrateur :
- détecteur: Chargé via les lignes 26-29 . Nous utilisons un détecteur de visage DL basé sur Caffe pour localiser les visages dans une image.
- enrober: Chargé sur la ligne 33 . Ce modèle est basé sur Torch et est responsable de l' extraction des intégrations faciales via l'extraction de fonctionnalités d'apprentissage en profondeur.
Notez que nous utilisons le respectif
À l'avenir, récupérons nos chemins d'image et effectuons des initialisations :
→ Lancer Jupyter Notebook sur Google ColabLa
Nos imbrications et noms correspondants seront tenus dans deux listes :
Nous garderons également une trace du nombre de visages que nous avons traités via une variable appelée
Commençons à boucler sur les chemins d'image - cette boucle sera responsable de l'extraction des incorporations des visages trouvés dans chaque image :
→ Lancer Jupyter Notebook sur Google ColabNous commençons à boucler
Dans un premier temps, nous extrayons le
Remarquez comment en utilisant
Enfin, nous terminons le bloc de code ci-dessus en chargeant le
Détectons et localisons les visages :
→ Lancer Jupyter Notebook sur Google ColabAux lignes 62-64 , nous construisons un blob. Pour en savoir plus sur ce processus, veuillez lire Deep learning: How OpenCV's blobFromImage works .
De là, nous détectons les visages dans l'image en passant le
Traitons le
La
En supposant que nous ayons au moins une détection, nous allons passer au corps de l'instruction if ( Ligne 72 ).
Nous faisons l'hypothèse qu'il n'y a qu'un seul visage dans l'image, nous extrayons donc la détection avec le plus haut
En supposant que nous avons atteint ce seuil, nous extrayons le
À partir de là, nous profiterons de notre
Nous construisons un autre blob, cette fois à partir du ROI du visage (pas de l'image entière comme nous l'avons fait auparavant) sur les lignes 98 et 99 .
Par la suite, nous passons le
Et puis nous ajoutons simplement le
Nous ne pouvons pas non plus oublier la variable que nous avons définie pour suivre le
Nous poursuivons ce processus de boucle sur les images, de détection des visages et d'extraction des incorporations de visage pour chaque image de notre ensemble de données.
À la fin de la boucle, il ne reste plus qu'à vider les données sur le disque :
→ Lancer Jupyter Notebook sur Google ColabNous ajoutons le nom et les données d'intégration à un dictionnaire, puis sérialisons le
À ce stade, nous sommes prêts à extraire les représentations incorporées en exécutant notre script.
Pour suivre ce didacticiel de reconnaissance faciale, utilisez la section "Téléchargements" du message pour télécharger le code source, les modèles OpenCV et un exemple d'ensemble de données de reconnaissance faciale.
À partir de là, ouvrez un terminal et exécutez la commande suivante pour calculer les incorporations de visage avec OpenCV :
→ Lancer Jupyter Notebook sur Google ColabIci, vous pouvez voir que nous avons extrait 18 incorporations de visage, une pour chacune des images (6 par classe) dans notre ensemble de données de visage d'entrée.
Étape 2 : Entraînez le modèle de reconnaissance faciale
À ce stade, nous avons extrait des intégrations 128-d pour chaque visage - mais comment reconnaissons-nous réellement une personne sur la base de ces intégrations ? La réponse est que nous devons former un modèle d'apprentissage automatique "standard" (tel qu'un SVM, un classificateur k-NN, une forêt aléatoire, etc.) en plus des incorporations.
Dans mon précédent didacticiel sur la reconnaissance faciale, nous avons découvert comment une version modifiée de k-NN peut être utilisée pour la reconnaissance faciale sur des intégrations 128-d créées via les bibliothèques dlib et face_recognition .
Aujourd'hui, je souhaite partager comment nous pouvons créer un classificateur plus puissant en plus des incorporations - vous pourrez également utiliser cette même méthode dans vos pipelines de reconnaissance faciale basés sur dlib si vous le souhaitez.
Ouvrez le
Nous aurons besoin de scikit-learn , une bibliothèque d'apprentissage automatique, installée dans notre environnement avant d'exécuter ce script. Vous pouvez l'installer via pip :
→ Lancer Jupyter Notebook sur Google ColabNous importons nos packages et modules sur les lignes 2-5 . Nous utiliserons l'implémentation de scikit-learn de Support Vector Machines (SVM), un modèle d'apprentissage automatique courant.
À partir de là, nous analysons nos arguments de ligne de commande :
- --encastrements: Le chemin vers les représentations vectorielles continues sérialisées (nous l'avons exporté en exécutant le précédentextract_embeddings.pyscénario).
- --recognizer: Ce sera notre modèle de sortie qui reconnaît les visages. Il est basé sur SVM. Nous allons l'enregistrer afin de pouvoir l'utiliser dans les deux prochains scripts de reconnaissance.
- --le: chemin du fichier de sortie de notre encodeur d'étiquettes. Nous sérialiserons notre encodeur d'étiquettes sur disque afin de pouvoir l'utiliser ainsi que le modèle de reconnaissance dans nos scripts de reconnaissance faciale image/vidéo.
Chacun de ces arguments est obligatoire .
Chargeons nos incorporations faciales et encodons nos étiquettes :
→ Lancer Jupyter Notebook sur Google ColabIci, nous chargeons nos incorporations de l' étape 1 sur la ligne 19 . Nous ne générerons aucune représentation vectorielle continue dans ce script de formation de modèle ; nous utiliserons les représentations vectorielles continues précédemment générées et sérialisées.
Ensuite, nous initialisons notre scikit-learn
Il est maintenant temps d'entraîner notre modèle SVM pour la reconnaissance des visages :
→ Lancer Jupyter Notebook sur Google ColabSur la ligne 29, nous initialisons notre modèle SVM, et sur la ligne 30, nous
Ici, nous utilisons une machine à vecteurs de support linéaire (SVM), mais vous pouvez essayer d'expérimenter d'autres modèles d'apprentissage automatique si vous le souhaitez.
Après avoir entraîné le modèle, nous produisons le modèle et l'encodeur d'étiquettes sur le disque sous forme de fichiers pickle.
→ Lancer Jupyter Notebook sur Google ColabNous écrivons deux fichiers pickle sur le disque dans ce bloc — le modèle de reconnaissance faciale et l' encodeur d'étiquettes .
À ce stade, assurez-vous d'avoir exécuté le code de l' étape 1 en premier. Vous pouvez récupérer le zip contenant le code et les données dans la section "Téléchargements" .
Maintenant que nous avons fini de coder
Ici, vous pouvez voir que notre SVM a été formé sur les intégrations et que (1) le SVM lui-même et (2) le codage d'étiquette ont été écrits sur le disque, ce qui nous permet de les appliquer aux images et vidéos d'entrée.
Étape 3 : Reconnaître les visages avec OpenCV
Nous sommes maintenant prêts à effectuer la reconnaissance faciale avec OpenCV !
Nous commencerons par reconnaître les visages dans les images dans cette section, puis passerons à la reconnaissance des visages dans les flux vidéo dans la section suivante.
Ouvrez le
Nous
Nos six arguments de ligne de commande sont analysés sur les lignes 10-23 :
- --image: chemin d'accès à l'image d'entrée. Nous allons essayer de reconnaître les visages sur cette image.
- --détecteur: Le chemin vers le détecteur de visage d'apprentissage en profondeur d'OpenCV. Nous utiliserons ce modèle pour détecter où se trouvent les ROI du visage dans l'image.
- --embedding-model: Le chemin vers le modèle d'intégration de visage d'apprentissage en profondeur d'OpenCV. Nous utiliserons ce modèle pour extraire l'intégration du visage 128-D de la ROI du visage - nous transmettrons les données au module de reconnaissance.
- --recognizer: Le chemin vers notre modèle de reconnaissance. Nous avons formé notre module de reconnaissance SVM à l' étape 2 . C'est ce qui déterminera réellement qui est un visage.
- --le: Le chemin vers notre encodeur d'étiquettes. Celui-ci contient nos étiquettes faciales telles que'adrien'ou'tricha'.
- --confiance: Le seuil facultatif pour filtrer les détections de visage faibles .
Assurez-vous d'étudier ces arguments de ligne de commande - il est important de connaître la différence entre les deux modèles d'apprentissage en profondeur et le modèle SVM. Si vous vous trouvez confus plus tard dans ce script, vous devriez vous référer ici.
Maintenant que nous avons géré nos importations et nos arguments de ligne de commande, chargeons les trois modèles du disque en mémoire :
→ Lancer Jupyter Notebook sur Google ColabNous chargeons trois modèles dans ce bloc. Au risque d'être redondant, je tiens à rappeler explicitement les différences entre les modèles :
- détecteur: Un modèle Caffe DL pré-formé pour détecter où se trouvent les visages dans l'image ( Lignes 27-30 ).
- enrober: Un modèle Torch DL pré-entraîné pour calculer nos plongements de visage 128-D ( Ligne 34 ).
- reconnaisseur: Notre modèle de reconnaissance faciale linéaire SVM ( Line 37 ). Nous avons formé ce modèle à l' étape 2 .
Les deux 1 et 2 sont pré-formés , ce qui signifie qu'ils vous sont fournis tels quels par OpenCV. Ils sont enterrés dans le projet OpenCV sur GitHub, mais je les ai inclus pour votre commodité dans la section "Téléchargements" de l'article d'aujourd'hui. J'ai également numéroté les modèles dans l'ordre dans lequel nous les appliquerons pour reconnaître les visages avec OpenCV.
Nous chargeons également notre encodeur d'étiquettes qui contient les noms des personnes que notre modèle peut reconnaître ( Ligne 38 ).
Maintenant, chargeons notre image et détectons les visages :
→ Lancer Jupyter Notebook sur Google ColabIci, nous :
- Chargez l'image en mémoire et construisez un blob ( Lignes 42-49 ). En savoir pluscv2.dnn.blobFromImageici .
- Localisez les visages dans l'image via notredétecteur( Lignes 53 et 54 ).
Compte tenu de notre nouveau
Vous reconnaîtrez ce bloc à partir de l' étape 1 . Je vais l'expliquer ici une fois de plus:
- On boucle sur ledétectionssur la ligne 57 et extrayez leconfiancede chacun sur la ligne 60 .
- Puis on compare leconfianceau seuil minimum de détection de probabilité contenu dans notre ligne de commandeargumentsdictionnaire, en veillant à ce que la probabilité calculée soit supérieure à la probabilité minimale ( Ligne 63 ).
- De là, on extrait leVisageROI ( Lignes 66-70 ) et assurez-vous que ses dimensions spatiales sont suffisamment grandes ( Lignes 74 et 75 ).
Reconnaissant le nom du
Dans un premier temps, nous construisons un
Ensuite, nous passons le
Nous prenons l'indice de probabilité le plus élevé ( Ligne 87 ) et interrogeons notre encodeur d'étiquettes pour trouver le
Remarque : vous pouvez filtrer davantage les reconnaissances faciales faibles en appliquant un test de seuil supplémentaire sur la probabilité. Par exemple, en insérant
Maintenant, affichons les résultats de la reconnaissance faciale OpenCV :
Pour chaque visage que nous reconnaissons dans la boucle (y compris les personnes "inconnues") :
- Nous construisons untextechaîne contenant leNomet probabilité sur la ligne 93 .
- Et puis nous dessinons un rectangle autour du visage et plaçons le texte au-dessus de la boîte ( Lignes 94-98 ).
Et puis enfin on visualise les résultats à l'écran jusqu'à ce qu'une touche soit enfoncée ( Lignes 101 et 102 ).
Il est temps de reconnaître les visages dans les images avec OpenCV !
Pour appliquer notre pipeline de reconnaissance faciale OpenCV à mes images fournies (ou à votre propre ensemble de données + images de test), assurez-vous d'utiliser la section "Téléchargements" du billet de blog pour télécharger le code, les modèles formés et les exemples d'images.
De là, ouvrez un terminal et exécutez la commande suivante :
→ Lancer Jupyter Notebook sur Google Colab
Ici, vous pouvez me voir en train de siroter une bière et de porter l'un de mes t-shirts préférés de Jurassic Park , ainsi qu'un verre à pinte spécial Jurassic World et un livre commémoratif. Ma prédiction de visage n'a qu'une confiance de 47,15 % ; cependant, cette confiance est plus élevée que la classe « Inconnu » .
Essayons un autre exemple de reconnaissance faciale OpenCV :
→ Lancer Jupyter Notebook sur Google Colab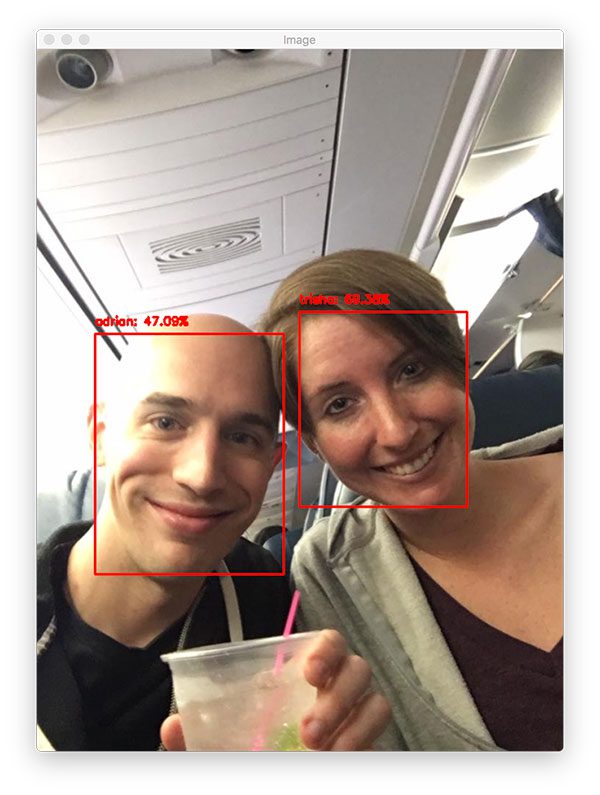
Voici Trisha et moi, prêts à commencer nos vacances !
Dans un dernier exemple, regardons ce qui se passe lorsque notre modèle est incapable de reconnaître le visage réel :
→ Lancer Jupyter Notebook sur Google Colab
La troisième image est un exemple d'une personne "inconnue" qui est en fait Patrick Bateman d' American Psycho - croyez-moi, ce n'est pas une personne que vous voudriez voir apparaître dans vos images ou flux vidéo !
BONUS : Reconnaître les visages dans les flux vidéo
En bonus, j'ai décidé d'inclure une section dédiée à la reconnaissance faciale OpenCV dans les flux vidéo !
Le pipeline lui-même est presque identique à la reconnaissance des visages dans les images, avec seulement quelques mises à jour que nous examinerons en cours de route.
Ouvrez le
Nos importations sont les mêmes que celles de l' étape 3 ci-dessus, à l'exception des lignes 2 et 3 où nous utilisons le
Les arguments de la ligne de commande sont également les mêmes, sauf que nous ne transmettons pas de chemin vers une image statique via la ligne de commande. Au lieu de cela, nous allons saisir une référence à notre webcam, puis traiter la vidéo. Reportez-vous à l' étape 3 si vous avez besoin de revoir les arguments.
Nos trois modèles et l'encodeur d'étiquettes sont chargés ici :
→ Lancer Jupyter Notebook sur Google ColabIci, nous chargeons le visage
Encore une fois, assurez-vous de vous référer à l' étape 3 si vous êtes confus au sujet des trois modèles ou de l'encodeur d'étiquettes.
Initialisons notre flux vidéo et commençons à traiter les images :
→ Lancer Jupyter Notebook sur Google ColabNotre
Nous initialisons également notre compteur d' images par seconde ( ligne 47 ) et commençons à boucler sur les images de la ligne 50 . Nous attrapons un
À partir de là, tout est identique à l' étape 3 . Nous
Traitons maintenant les détections :
→ Lancer Jupyter Notebook sur Google ColabTout comme dans la section précédente, nous commençons à boucler
Il est maintenant temps d'effectuer la reconnaissance faciale OpenCV :
→ Lancer Jupyter Notebook sur Google ColabIci, nous :
- Construire lefaceBlob( Lignes 94 et 95 ) et calculez les incorporations faciales via le deep learning ( Lignes 96 et 97 ).
- Reconnaître le plus probableNomdu visage lors du calcul de la probabilité ( Ligne 100-103 ).
- Dessinez une boîte englobante autour du visage et de la personneNom+ probabilité ( Lignes 107 -112 ).
Notre
Affichons les résultats et nettoyons :
→ Lancer Jupyter Notebook sur Google ColabPour clôturer le script, nous :
- Afficher les annotésCadre( Ligne 118 ) et attendez que la touche "q" soit enfoncée à quel point nous sortons de la boucle ( Lignes 119-123 ).
- Arrêtez notreipscompteur et imprimer les statistiques dans le terminal ( Lignes 126-128 ).
- Nettoyage en fermant les fenêtres et en relâchant les pointeurs ( Lignes 131 et 132 ).
Pour exécuter notre pipeline de reconnaissance faciale OpenCV sur un flux vidéo, ouvrez un terminal et exécutez la commande suivante :
→ Lancer Jupyter Notebook sur Google Colab
Figure 7 : Reconnaissance faciale en vidéo avec OpenCV.
Comme vous pouvez le voir, Trisha et mon visage sont correctement identifiés ! Notre pipeline de reconnaissance faciale OpenCV obtient également ~ 16 FPS sur mon iMac. Sur mon MacBook Pro, j'obtenais un débit d'environ 14 FPS.
Inconvénients, limites et comment obtenir une plus grande précision de reconnaissance faciale

Inévitablement, vous vous retrouverez dans une situation où OpenCV ne reconnaît pas correctement un visage.
Que faites-vous dans ces situations ?
Et comment améliorez-vous la précision de votre reconnaissance faciale OpenCV ? Dans cette section, je détaillerai quelques-unes des méthodes suggérées pour augmenter la précision de votre pipeline de reconnaissance faciale
Vous aurez peut-être besoin de plus de données

Ma première suggestion est probablement la plus évidente, mais elle vaut la peine d'être partagée.



Commentaires
Enregistrer un commentaire