RESEAU DE NEURONE CONVOLUTIF
Vue d'ensemble
Architecture d'un CNN traditionnelLes réseaux de neurones convolutionnels (en anglais Convolutional neural networks), aussi connus sous le nom de CNNs, sont un type spécifique de réseaux de neurones qui sont généralement composés des couches suivantes :

La couche convolutionnelle et la couche de pooling peuvent être ajustées en utilisant des paramètres qui sont décrites dans les sections suivantes.
Types de couche
Couche convolutionnelle (CONV)La couche convolutionnelle (en anglais convolution layer) (CONV) utilise des filtres qui scannent l'entrée suivant ses dimensions en effectuant des opérations de convolution. Elle peut être réglée en ajustant la taille du filtre et le stride . La sortie de cette opération est appelée feature map ou aussi activation map.
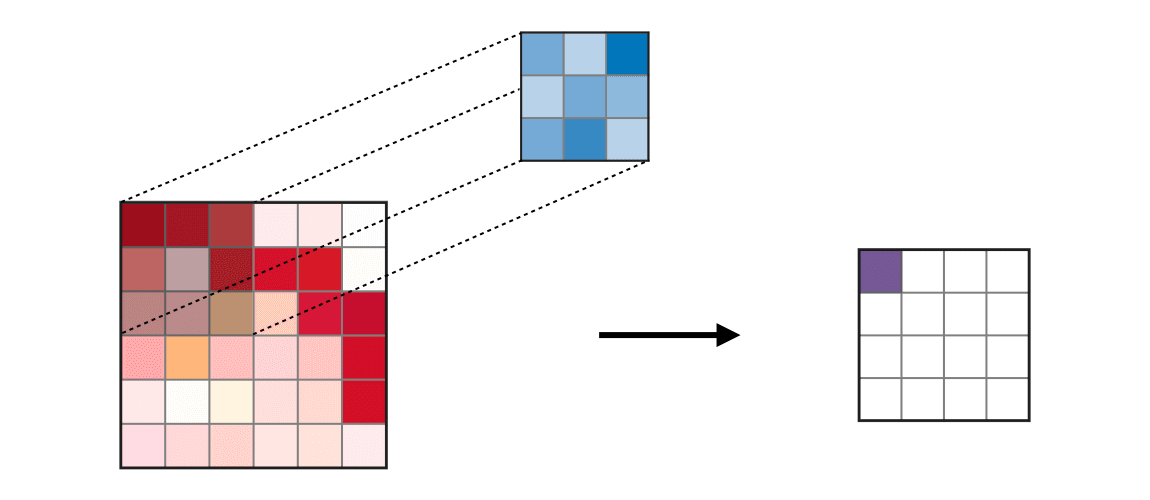
Remarque : l'étape de convolution peut aussi être généralisée dans les cas 1D et 3D.
Pooling (POOL)La couche de pooling (en anglais pooling layer) (POOL) est une opération de sous-échantillonnage typiquement appliquée après une couche convolutionnelle. En particulier, les types de pooling les plus populaires sont le max et l'average pooling, où les valeurs maximales et moyennes sont prises, respectivement.
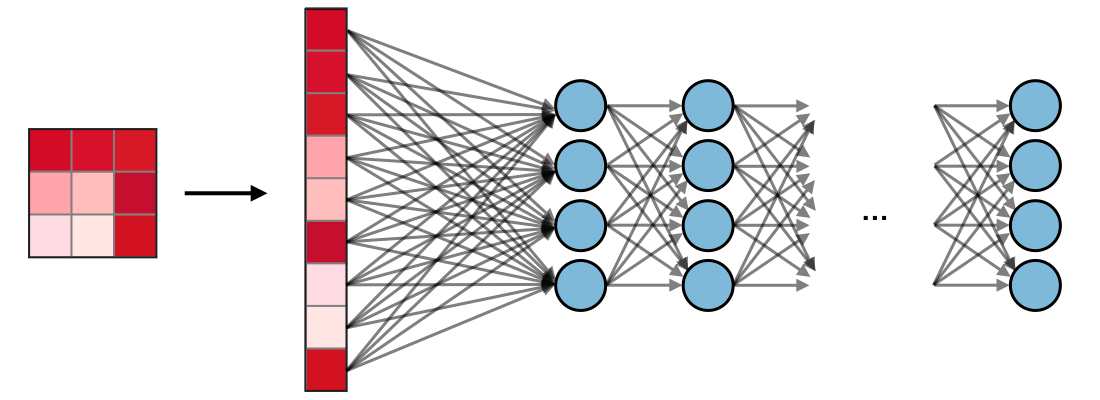
Fully Connected (FC)La couche de fully connected (en anglais fully connected layer) (FC) s'applique sur une entrée préalablement aplatie où chaque entrée est connectée à tous les neurones. Les couches de fully connected sont typiquement présentes à la fin des architectures de CNN et peuvent être utilisées pour optimiser des objectifs tels que les scde classe.
Paramètres du filtre
La couche convolutionnelle contient des filtres pour lesquels il est important de savoir comment ajuster ses paramètres.
Dimensions d'un filtreUn filtre de taille appliqué à une entrée contenant canaux est un volume de taille qui effectue des convolutions sur une entrée de taille et qui produit un feature map de sortie (aussi appelé activation map) de taille .

Remarque : appliquer filtres de taille engendre un feature map de sortie de taille .
StrideDans le contexte d'une opération de convolution ou de pooling, la stride est un paramètre qui dénote le nombre de pixels par lesquels la fenêtre se déplace après chaque opération.

Zero-paddingLe zero-padding est une technique consistant à ajouter zeros à chaque côté des frontières de l'entrée. Cette valeur peut être spécifiée soit manuellement, soit automatiquement par le biais d'une des configurations détaillées ci-dessous :
Réglage des paramètres
Compatibilité des paramètres dans la couche convolutionnelleEn notant le côté du volume d'entrée, la taille du filtre, la quantité de zero-padding, la stride, la taille de la feature map de sortie suivant cette dimension est telle que :

Remarque : on a souvent , auquel cas on remplace par dans la formule au-dessus.
Comprendre la complexité du modèlePour évaluer la complexité d'un modèle, il est souvent utile de déterminer le nombre de paramètres que l'architecture va avoir. Dans une couche donnée d'un réseau de neurones convolutionnels, on a :
Champ récepteurLe champ récepteur à la couche est la surface notée de l'entrée que chaque pixel de la -ième activation map peut 'voir'. En notant la taille du filtre de la couche et la valeur de stride de la couche et avec la convention , le champ récepteur à la couche peut être calculé de la manière suivante :
Dans l'exemple ci-dessous, on a et , ce qui donne .

Fonctions d'activation communément utilisées
Unité linéaire rectifiéeLa couche d'unité linéaire rectifiée (en anglais rectified linear unit layer) (ReLU) est une fonction d'activation qui est utilisée sur tous les éléments du volume. Elle a pour but d'introduire des complexités non-linéaires au réseau. Ses variantes sont récapitulées dans le tableau suivant :
| ReLU | Leaky ReLU | ELU |
with | with | |
 |  |  |
| • Complexités non-linéaires interprétables d'un point de vue biologique | • Répond au problème de dying ReLU | • Dérivable partout |
SoftmaxL'étape softmax peut être vue comme une généralisation de la fonction logistique qui prend comme argument un vecteur de scores et qui renvoie un vecteur de probabilités à travers une fonction softmax à la fin de l'architecture. Elle est définie de la manière suivante :
Détection d'objet
Types de modèlesIl y a 3 principaux types d'algorithme de reconnaissance d'objet, pour lesquels la nature de ce qui est prédit est different. Ils sont décrits dans la table ci-dessous :
| Classification d'image | Classification avec localisation | Détection |
 |  |  |
| • Classifie une image • Prédit la probabilité d'un objet | • Détecte un objet dans une image • Prédit la probabilité de présence d'un objet et où il est situé | • Peut détecter plusieurs objets dans une image • Prédit les probabilités de présence des objets et où ils sont situés |
| CNN traditionnel | YOLO simplifié, R-CNN | YOLO, R-CNN |
DétectionDans le contexte de la détection d'objet, des méthodes différentes sont utilisées selon si l'on veut juste localiser l'objet ou alors détecter une forme plus complexe dans l'image. Les deux méthodes principales sont résumées dans le tableau ci-dessous :
| Détection de zone délimitante | Détection de forme complexe |
| • Détecte la partie de l'image où l'objet est situé | • Détecte la forme ou les caractéristiques d'un objet (e.g. yeux) • Plus granulaire |
 |  |
| Zone de centre , hauteur et largeur | Points de référence |
Intersection sur UnionIntersection sur Union (en anglais Intersection over Union), aussi appelé , est une fonction qui quantifie à quel point la zone délimitante prédite est correctement positionnée par rapport à la zone délimitante vraie . Elle est définie de la manière suivante :
Remarque : on a toujours . Par convention, la prédiction d'une zone délimitante est considérée comme étant satisfaisante si l'on a .

Zone d'accrocheLa technique des zones d'accroche (en anglais anchor boxing) sert à prédire des zones délimitantes qui se chevauchent. En pratique, on permet au réseau de prédire plus d'une zone délimitante simultanément, où chaque zone prédite doit respecter une forme géométrique particulière. Par exemple, la première prédiction peut potentiellement être une zone rectangulaire d'une forme donnée, tandis qu'une seconde prédiction doit être une zone rectangulaire d'une autre forme.
Suppression non-maxLa technique de suppression non-max (en anglais non-max suppression) a pour but d'enlever des zones délimitantes qui se chevauchent et qui prédisent un seul et même objet, en sélectionnant les zones les plus représentatives. Après avoir enlevé toutes les zones ayant une probabilité prédite de moins de 0.6, les étapes suivantes sont répétées pour éliminer les zones redondantes :
Pour une classe donnée,
• Étape 1 : Choisir la zone ayant la plus grande probabilité de prédiction.
• Étape 2 : Enlever toute zone ayant avec la zone choisie précédemment.

YOLOL'algorithme You Only Look Once (YOLO) est un algorithme de détection d'objet qui fonctionne de la manière suivante :
• Étape 1 : Diviser l'image d'entrée en une grille de taille .
• Étape 2 : Pour chaque cellule, faire tourner un CNN qui prédit de la forme suivante :
• Étape 3 : Faire tourner l'algorithme de suppression non-max pour enlever des doublons potentiels qui chevauchent des zones délimitantes.

Remarque : lorsque , le réseau ne détecte plus d'objet. Dans ce cas, les prédictions correspondantes doivent être ignorées.
R-CNNL'algorithme de région avec des réseaux de neurones convolutionnels (en anglais Region with Convolutional Neural Networks) (R-CNN) est un algorithme de détection d'objet qui segmente l'image d'entrée pour trouver des zones délimitantes pertinentes, puis fait tourner un algorithme de détection pour trouver les objets les plus probables d'apparaître dans ces zones délimitantes.

Remarque : bien que l'algorithme original soit lent et coûteux en temps de calcul, de nouvelles architectures ont permis de faire tourner l'algorithme plus rapidement, tels que le Fast R-CNN et le Faster R-CNN.
Vérification et reconnaissance de visage
Types de modèlesDeux principaux types de modèle sont récapitulés dans le tableau ci-dessous :
| Vérification de visage | Reconnaissance de visage |
| • Est-ce la bonne personne ? • Un à un | • Est-ce une des personnes dans la base de données ? • Un à plusieurs |
 |  |
Apprentissage par coupL'apprentissage par coup (en anglais One Shot Learning) est un algorithme de vérification de visage qui utilise un training set de petite taille pour apprendre une fonction de similarité qui quantifie à quel point deux images données sont différentes. La fonction de similarité appliquée à deux images est souvent notée
Réseaux siamoisLes réseaux siamois (en anglais Siamese Networks) ont pour but d'apprendre comment encoder des images pour quantifier le degré de différence de deux images données. Pour une image d'entrée donnée , l'encodage de sortie est souvent notée .
Loss tripleLe loss triple (en anglais triplet loss) est une fonction de loss calculée sur une représentation encodée d'un triplet d'images (accroche), (positif), et (négatif). L'exemple d'accroche et l'exemple positif appartiennent à la même classe, tandis que l'exemple négatif appartient à une autre. En notant le paramètre de marge, le loss est défini de la manière suivante :


Transfert de style neuronal
MotivationLe but du transfert de style neuronal (en anglais neural style transfer) est de générer une image à partir d'un contenu et d'un style .

ActivationDans une couche donnée, l'activation est notée et est de dimensions .
Fonction de coût de contenuLa fonction de coût de contenu (en anglais content cost function), notée , est utilisée pour quantifier à quel point l'image générée diffère de l'image de contenu original . Elle est définie de la manière suivante :
Matrice de styleLa matrice de style (en anglais style matrix) d'une couche donnée est une matrice de Gram dans laquelle chacun des éléments quantifie le degré de corrélation des canaux and . Elle est définie en fonction des activations de la manière suivante :
Remarque : les matrices de style de l'image de style et de l'image générée sont notées and respectivement.
Fonction de coût de styleLa fonction de coût de style (en anglais style cost function), notée , est utilisée pour quantifier à quel point l'image générée diffère de l'image de style . Elle est définie de la manière suivante :
Fonction de coût totalLa fonction de coût total (en anglais overall cost function) est définie comme étant une combinaison linéaire des fonctions de coût de contenu et de style, pondérées par les paramètres , de la manière suivante :
Remarque : plus est grand, plus le modèle privilégiera le contenu et plus est grand, plus le modèle sera fidèle au style.
Architectures utilisant des astuces de calcul
Réseau antagoniste génératifLes réseaux antagonistes génératifs (en anglais generative adversarial networks), aussi connus sous le nom de GANs, sont composés d'un modèle génératif et d'un modèle discriminant, où le modèle génératif a pour but de générer des prédictions aussi réalistes que possibles, qui seront ensuite envoyées dans un modèle discriminant qui aura pour but de différencier une image générée d'une image réelle.

Remarque : les GANs sont utilisées dans des applications pouvant aller de la génération de musique au traitement de texte vers image.
ResNetL'architecture du réseau résiduel (en anglais Residual Network), aussi appelé ResNet, utilise des blocs résiduels avec un nombre élevé de couches et a pour but de réduire l'erreur de training. Le bloc résiduel est caractérisé par l'équation suivante :
Inception NetworkCette architecture utilise des modules d'inception et a pour but de tester toute sorte de configuration de convolution pour améliorer sa performance en diversifiant ses attributs. En particulier, elle utilise l'astuce de la convolution
pour limiter sa complexité de calcul.



Commentaires
Enregistrer un commentaire